В вашей организации есть несколько вакантных должностей, и вы планируете использовать Google Forms для подготовки анкеты перед собеседованием для соискателей. Вы создали форму, в которой есть все стандартные поля, в которые кандидаты могут ввести свое имя, адрес электронной почты, URL-адрес веб-сайта, номер телефона, почтовый индекс и другие важные данные.
Форма готова для публикации в Интернете, но как вы можете убедиться, что кандидаты ввели данные в правильном формате, прежде чем опубликовать ее? И даже если формат правильный, верны ли сами данные? Можете ли вы добавить CAPTCHA в формы Google, чтобы предотвратить спам-боты? Можно ли включить фильтр ненормативной лексики, чтобы запретить людям отправлять записи, содержащие нецензурные выражения?
Когда вы ожидаете десятки или даже сотен, от ответов в ваших формах Google, всегда хорошая идея, чтобы некоторые правила, и данные респонденты должны быть сопоставлены с этими правилами даже до того, как они будут представить форму. Например, если ваша форма просит в год рождения человека, им следует разрешать только ввести число между 1900 и 2014 годом.

Google Forms позволяет относительно легко добавлять такие расширенные правила проверки даты в отдельные поля с помощью регулярных выражений (или регулярных выражений или регулярных выражений). Думайте о них как о шаблонах поиска, и каждый символ, введенный в поле формы, сопоставляется с этим шаблоном — форма может быть отправлена только в том случае, если шаблон и ввод пользователя совпадают.
Давайте разберемся в этом на реальном примере.
Допустим, ваша форма Google ожидает, что пользователь введет год своего рождения. Во время разработки формы разверните раздел «Проверка данных» под полем формы (см. Снимок экрана выше) и выберите «Регулярное выражение» из раскрывающегося списка. Затем выберите «Совпадения» в другом раскрывающемся списке и введите ^(19d{2}|20[0-1]d)$ в поле ввода. Поле теперь будет принимать входное значение, например 1920, 2010, но отклонять другие значения, выходящие за пределы диапазона.
Регулярные выражения для общих полей формы
Регулярное выражение может появиться гибберски, но они не так сложно читать и понять, если вы можете знать основные правила языка. То, что вы видите здесь, является компиляцией некоторых полезных регулярных выражений, которые можно использовать для проверки общих полей формы, такие как URL, номера телефонов, почтовых индексов, даты и т. Д.
1 . Почтовый адрес — разрешить в поле ввода формы только буквенно-цифровые символы, пробелы и некоторые другие символы, такие как запятая, точка и решетка.
[a-zA-Zds-,#.+]+
2 . Почтовый индекс — регулярное выражение позволяет использовать почтовые индексы в стандартных форматах и соответствует как американским, так и индийским почтовым индексам.
^d{5,6}(?:[-s]d{4})?$
3 . Дата — принять ввод даты в форматах mm/dd/yyyy или mm-dd-yyyy
((0[1-9])|(1[0-2]))[/-]((0[1-9])|(1[0-9])|(2[0-9])|(3[0-1]))[/-](d{4})
4 . Адрес электронной почты — приведенное ниже регулярное выражение должно соответствовать наиболее распространенным форматам адресов электронной почты, включая псевдонимы Gmail, которые принимают знак «+», но нет идеальное решение.
[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+
5 . URL-адрес (веб-домен) — это полезно для полей, которые требуют, чтобы пользователь вводил адрес своего веб-сайта, и он даже соответствует будущим TLD. например.directory или.restaurant. Другое регулярное выражение соответствует URL-адресу YouTube, включая те, которые используют домены youtu.be
https?://[a-zA-Z0-9-.]+.[a-zA-Z]{2,}
https?://(www.)?youtu(.)?be(.com)?/.*(?v=|/v/)?[a-zA-Z0-9_-]+
6 . Предел символов — текстовое поле по умолчанию в форме Google позволяет пользователям вводить любое количество символов, но вы можете наложить предел с помощь регулярного выражения. Здесь мы ограничиваем вход на 140 символов, как твиттер.
[w]{1,140}
7 . Номера телефонов — часто это набор цифр, перед которым стоит необязательный знак «+», а код города может быть заключен в квадратные скобки.
+?(?d{2,4})?[ds-]{3,}
8 . Цена (с десятичным числом) — если в поле формы требуется, чтобы пользователи вводили цену товара в своей валюте, это регулярное выражение будет помощь. Замените знак $ собственным символом валюты.
$?d{1,3}(,?d{3})*(.d{1,2})?
9 . Сложный пароль — принимает только строку, состоящую из 1 прописного алфавита, 1 строчного алфавита, 2 цифр и 1 специального символа. Также минимально допустимая длина составляет 8 символов.
(?=.*[A-Z])(?=.*[a-z])(?=.*[0-9].*[0-9])(?=.*[^a-zA-Z0-9]).{8,}
10 . CAPTCHA — формы Google не предлагают CAPTCHA, но вы можете создать ее с помощью регулярного выражения. Вот простая капча, которая требует от пользователей ответа на простой вопрос — что такое 2 + 2?
^(4|[Ff][Oo][Uu][Rr])$
11 . Ограничение по количеству слов — если вы хотите ограничить количество слов, которые пользователь может вводить в поле ввода формы Google, для этого тоже есть регулярное выражение. В этом случае мы разрешаем вводить только от 10 до 15 слов:
^[-w]+(?:W+[-w]+){9,14}W*$
Тоже столкнулся с проблемой валидизации телефонных номеров.
Телефоны берутся с участников вебинаров, на которые записываются люди из очень разных стран.
Соответственно, со всеми предыдущими схемами возникают проблемы:
1) а что если телефон с Украины (не +7-, а +38-)? А из Казахстана? А США (1-)? А Уганда ( +233-)? (из Уганды, правда, пока слушателей не было, но все впереди).
2)В разных местностях приняты самые невообразимые способы разбиения телефона на группы цифр:
8(8888)8-88-88-88 например. или 888(88)88888-888. Да и какие угодно могут возникнуть в будущем.
Поэтому вариант с «дефолтным разбиением типа «8(888)888-88-88 ну совершенно не катит.
Соответственно, я придумал следующий валидатор:
1) В начале могут быть пробелы, после них может быть «+» (а может и не быть)
2) Дальше должна идти группа цифр в количестве от 10 до 14 (мне нужны номера в международном формате; но если кому-то нужны более короткие — можно исправить диапазон длин).
3) Поскольку я не знаю, как люди группируют цифры — до и после каждой цифры может быть один из 8 знаков («-«, » «, «_», «(«, «)», «:», «=», «+»). Это значит, что между двумя цифрами могут быть любые два из этих знаков.
В итоге получилось очень коротко и понятно )) :
/^(s*)?(+)?([- _():=+]?d[- _():=+]?){10,14}(s*)?$/
Съедает следующие телефоны:
+7(903)888-88-88
8(999)99-999-99
+380(67)777-7-777
001-541-754-3010
+1-541-754-3010
19-49-89-636-48018
+233 205599853
Как создавать правила в формах
Чтобы респонденты заполняли форму корректно, используйте правила. Например, если в поле нужно ввести электронный адрес, создайте правило, запрещающее ввод других данных.
Как настроить правило
- Откройте форму Google.
- Добавьте вопрос одного из следующих типов:
- текст (строка);
- текст (абзац);
- несколько из списка.
- Нажмите на значок
 .
. - Выберите Проверка ответов.
- Задайте настройки правила.
- В последнем поле введите сообщение об ошибке, которое респонденты будут получать, если нарушат правило.
Типы правил
Для каждого вопроса предусмотрены особые параметры проверки.
Текст (строка)
- Число
- Пример: целое число от 21 до 42.
- Текст
- Пример: ответ должен содержать определенное слово либо должен иметь формат адреса электронной почты или URL.
- Длина
- Пример: ответ должен содержать не более 500 или не менее 200 символов.
- Регулярное выражение. Создайте шаблон, которому должен соответствовать ответ. Подробнее…
Текст (абзац)
- Длина. Задайте минимальное или максимальное число символов в ответе.
- Пример: ответ должен содержать не более 500 или не менее 200 символов.
- Регулярное выражение. Создайте шаблон, которому должен соответствовать ответ. Подробнее…
Несколько из списка
- Выберите не менее. Укажите минимальное число ответов, которые должен выбрать респондент.
- Выберите не более. Укажите максимальное число ответов, которые может выбрать респондент.
- Выберите ровно. Укажите, сколько ответов должен выбрать респондент.
Регулярные выражения
Если вы хотите, чтобы ответы респондентов соответствовали нескольким критериям, используйте регулярные выражения. Они позволяют сравнивать ответы с заданным вами шаблоном.
Примеры регулярных выражений
Таблица содержит примеры некоторых регулярных выражений, поддерживаемых Google Документами. Вам доступны не только они, но и многие другие.
| Выражение | Описание | Пример | Результаты поиска | Не отобразится в результатах |
|---|---|---|---|---|
| . | На месте точки может быть любой символ. | с. | сом, стол, осока | том, порт |
| * | Символ перед звездочкой может присутствовать в слове, отсутствовать или повторяться несколько раз. | со* | сон, сн, сооон | сОн, соль |
| + | Символ перед знаком плюса повторяется один или несколько раз подряд. | со+н | сон, сооон | сн, сОн, соль |
| ? | Символ перед знаком вопроса может присутствовать или не присутствовать в слове. | со?н | сн, сон | сОн, соль |
| ^ | Знак вставки в начале регулярного выражения означает, что результат начинается с указанных в скобках символов или их сочетания. | ^[ст]он | сон, тон | не сон, и тон |
| $ | Знак доллара ставится в конец регулярного выражения. Это означает, что результат заканчивается одним или несколькими символами, расположенными перед $. | [ст]он$ | сон, тон, и тон | сонм, тонна |
| {A,B} | Часть выражения, заключенная в скобки, повторяется от А до В раз (на месте А и В нужно указать числа). | с(о{1,2})н | сон, соон | сн, сооон, сОн |
| [х], [ха], [ха5] | Только один символов, указанных в квадратных скобках, может содержаться в результате поиска. В скобки можно поместить любое выражение, в том числе одно из описанных выше в таблице. Например, запрос может выглядеть так: [ха,$5Сc] | c[оа]н | сон, сан | сн, сОн, сооон |
| [а-я] | Поиск символа в заданном диапазоне. Обычно используются диапазоны а-я, А-Я и 0-9. Их можно объединять между собой ([а-яА-Я0-9]) или комбинировать с другими выражениями из данной таблицы ([а-яА-Я,&*]. | c[а-о]н | сан, син, сен, сон | сн, сОн, сын |
| [^а-дБВГ] | Здесь знак вставки означает поиск символа, который не входит в указанный диапазон. | с[^ае]н | сон, сОн, сын, с$н | сн, сан, сен |
| s | Все символы пробелов. | сsн | с н, с[Tab]н | сн, сон, стон |
Примечание. Хотите найти в таблице символ, который входит в регулярные выражения (например, ^ или $)? Поставьте в начале запроса обратную косую черту (). Например, чтобы найти все упоминания символа $, введите $.
Вот несколько примеров использования регулярных выражений для поиска по таблице:
Поиск ячеек, содержащих суммы, указанные в долларах
Введите в строку поиска запрос ^$([0-9,]+)?[.][0-9]+
Это значит, что вы ищете сумму в долларах, которая начинается с любой цифры от 0 до 9 (или с запятой). Цифра может повторяться или не повторяться. Затем следует любая цифра от 0 до 9, повторяющаяся один или более раз. В результатах может отобразиться любая из следующих сумм: $4,666, $17,86, $7,76, $0,54, $900 001,00, $523 877 231,56.
Поиск почтовых индексов США
Введите в строку поиска следующую команду: [0-9]{5}(-[0-9]{4})?
Так вы найдете почтовые индексы США, состоящие из пяти цифр, дефиса (опционально) и четырехзначного цифрового кода.
Поиск имен, начинающихся со строчной буквы
Введите в строку поиска следующую команду: ^[a-я].*
Так вы найдете текст, начинающийся со строчной буквы, за которой следуют другие символы. В результатах поиска отобразятся ячейки, содержащие, например, такие слова: катя, лена, дМИТРИЙ, люБа.
Эта информация оказалась полезной?
Как можно улучшить эту статью?
Collection of regular expressions to validate user input in Google Forms quizzes and surveys.
Your organization has a few vacant positions and you are planning to use Google Forms to prepare a pre-interview questionnaire for job applicants. You have created a form and it has all the standard fields where candidates can fill-in their name, email address, phone number, zip code and other information.
The form has been prepared but before you make it live, how would you ensure that candidates have entered data in the correct format? And even if the format is proper, is the data itself valid? Can you add a CAPTCHA to Google forms to prevent spam bots? Can you include a profanity filter to block people from submitting entries that include obscene words?
When you are expecting dozens, or even hundreds, of responses in your Google Forms, it is always a good idea to have some rules in place and the respondents’ data be matched against these rules even before they submit the form. For instance, if your form is asking for a person’s year of birth, and the applicant’s age should be between 25 and 50, they should only be allowed to enter a number between 1970 and 1996 in the year of birth field.
")
Regular Expressions in Google Forms
Google Forms makes it relatively easy to add such advanced date validation rules to individual fields through Regular Expressions (or regex or regexp). Think of them as search patterns and every character entered in a form field is matched against that pattern — the form can only be submitted if the patter and the user-input matches.
Let’s understand this with a real-world example.
Say your Google form expects the user to enter their year of birth. At the time of designing the form, expand the “Data Validation” section below the form field (see screenshot above) and choose Regular Expression from the drop-down. Next select “Matches” in the other drop-down and enter the following regex:
The field will now accept input value like 1977, 1995 but would reject other values that fall outside the 1970..1996 range.

Regular Expressions for Common Form Fields
A regular expression may appear gibberish but they aren’t so difficult to read and understand if you can know the basic rules of the language. What you see here is a compilation of some useful regular expressions that can be used to validate common form fields like URLs, phone numbers, zip codes, dates, etc.
1. Postal Address — allow only alphanumeric characters, spaces and few other characters like comma, period and hash symbol in the form input field.
[a-zA-Zds-,#.+]+
2. ZIP Code — the regex allows ZIP codes in standard formats and it matches both US and Indian zip codes.
^d{5,6}(?:[-s]d{4})?$
3. Date — accept date input in the mm/dd/yyyy or mm-dd-yyyy formats.
((0[1-9])|(1[0-2]))[/-]((0[1-9])|(1[0-9])|(2[0-9])|(3[0-1]))[/-](d{4})
Also see: Get Google Form Data by Email
4. Email Address — the regex below should match most common email address formats, including Gmail aliases that accept the ”+” sign but there’s no perfect solution.
[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+
5. URL (Web domain) — this is useful for fields that require the user to enter their website address and it even matches the upcoming TLDs like .directory or .restaurant. The other regex matches YouTube URL including those using the youtu.be domains.
https?://[a-zA-Z0-9-.]+.[a-zA-Z]{2,}
https?://(www.)?youtu(.)?be(.com)?/.*(?v=|/v/)?[a-zA-Z0-9_-]+6. Character Limit — the default text box in a Google form allows users to input any number of characters but you can impose a limit with the help of regular expression. Here we limit the input to 140 characters much like Twitter.
[w]{1,140}
7. Phone Numbers — these are often a series of numbers preceded by an optional ”+” sign and the area code may be inside brackets.
+?(?d{2,4})?[ds-]{3,}
8. Price (with decimal) — if a form field requires users to enter a price of an item in their own currency, this regex will help. Replace the $ sign with your own currency symbol.
$?d{1,3}(,?d{3})*(.d{1,2})?
9. Complex Password — only accept a string that has 1 uppercase alphabet, 1 lowercase alphabet, 2 digits and 1 special character. Also the minimum allowed length is 8 characters.
(?=.*[A-Z])(?=.*[a-z])(?=.*[0-9].*[0-9])(?=.*[^a-zA-Z0-9]).{8,}
10. CAPTCHA — Google forms do not offer CAPTCHAs but you can create one using regex. Here’s a simple captcha that requires users to answer a simple question — what is 2+2?
^(4|[Ff][Oo][Uu][Rr])$
Also see: Regular Expressions for Gmail Search
11. Word Limit — If you would like to limit the number of words that a user can type in the input field of a Google Form, there’s a regex for that as well. In this case, we only allow any input that has between 10 to 15 words:
^[-w]+(?:W+[-w]+){9,14}W*$
I would also suggest looking at the «libphonenumber» Google Library. I know it is not regex but it does exactly what you want.
For example, it will recognize that:
15555555555
is a possible number but not a valid number. It also supports countries outside the US.
Highlights of functionality:
- Parsing/formatting/validating phone numbers for all countries/regions of the world.
getNumberType— gets the type of the number based on the number itself; able to distinguish Fixed-line, Mobile, Toll-free, Premium Rate, Shared Cost, VoIP and Personal Numbers (whenever feasible).isNumberMatch— gets a confidence level on whether two numbers could be the same.getExampleNumber/getExampleNumberByType— provides valid example numbers for all countries/regions, with the option of specifying which type of example phone number is needed.isPossibleNumber— quickly guessing whether a number is a possible phonenumber by using only the length information, much faster than a full validation.isValidNumber— full validation of a phone number for a region using length and prefix information.AsYouTypeFormatter— formats phone numbers on-the-fly when users enter each digit.findNumbers— finds numbers in text input.PhoneNumberOfflineGeocoder— provides geographical information related to a phone number.
Examples
The biggest problem with phone number validation is it is very culturally dependant.
- America
(408) 974–2042is a valid US number(999) 974–2042is not a valid US number
- Australia
0404 999 999is a valid Australian number(02) 9999 9999is also a valid Australian number(09) 9999 9999is not a valid Australian number
A regular expression is fine for checking the format of a phone number, but it’s not really going to be able to check the validity of a phone number.
I would suggest skipping a simple regular expression to test your phone number against, and using a library such as Google’s libphonenumber (link to GitHub project).
Introducing libphonenumber!
Using one of your more complex examples, 1-234-567-8901 x1234, you get the following data out of libphonenumber (link to online demo):
Validation Results
Result from isPossibleNumber() true
Result from isValidNumber() true
Formatting Results:
E164 format +12345678901
Original format (234) 567-8901 ext. 123
National format (234) 567-8901 ext. 123
International format +1 234-567-8901 ext. 123
Out-of-country format from US 1 (234) 567-8901 ext. 123
Out-of-country format from CH 00 1 234-567-8901 ext. 123
So not only do you learn if the phone number is valid (which it is), but you also get consistent phone number formatting in your locale.
As a bonus, libphonenumber has a number of datasets to check the validity of phone numbers, as well, so checking a number such as +61299999999 (the international version of (02) 9999 9999) returns as a valid number with formatting:
Validation Results
Result from isPossibleNumber() true
Result from isValidNumber() true
Formatting Results
E164 format +61299999999
Original format 61 2 9999 9999
National format (02) 9999 9999
International format +61 2 9999 9999
Out-of-country format from US 011 61 2 9999 9999
Out-of-country format from CH 00 61 2 9999 9999
libphonenumber also gives you many additional benefits, such as grabbing the location that the phone number is detected as being, and also getting the time zone information from the phone number:
PhoneNumberOfflineGeocoder Results
Location Australia
PhoneNumberToTimeZonesMapper Results
Time zone(s) [Australia/Sydney]
But the invalid Australian phone number ((09) 9999 9999) returns that it is not a valid phone number.
Validation Results
Result from isPossibleNumber() true
Result from isValidNumber() false
Google’s version has code for Java and Javascript, but people have also implemented libraries for other languages that use the Google i18n phone number dataset:
- PHP: https://github.com/giggsey/libphonenumber-for-php
- Python: https://github.com/daviddrysdale/python-phonenumbers
- Ruby: https://github.com/sstephenson/global_phone
- C#: https://github.com/twcclegg/libphonenumber-csharp
- Objective-C: https://github.com/iziz/libPhoneNumber-iOS
- JavaScript: https://github.com/ruimarinho/google-libphonenumber
- Elixir: https://github.com/socialpaymentsbv/ex_phone_number
Unless you are certain that you are always going to be accepting numbers from one locale, and they are always going to be in one format, I would heavily suggest not writing your own code for this, and using libphonenumber for validating and displaying phone numbers.
33 самые полезные регулярки с примерами использования для быстрого решения наиболее распространенных задач веб-разработки.
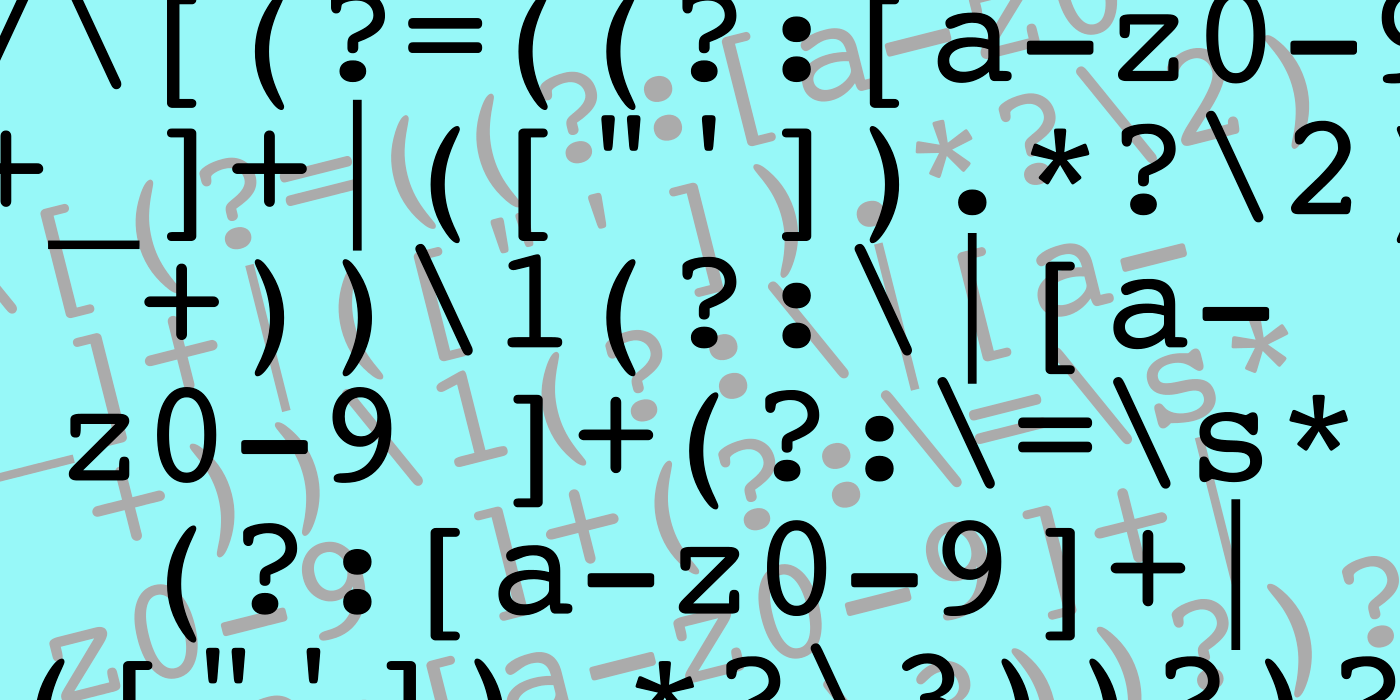
Пользовательские данные
1. Юзернейм
Стандартный формат юзернейма – цифры, строчные буквы, символы - и _. Разумная длина – от 3 до 16 знаков. В зависимости от ваших конкретных потребностей вы можете изменять набор символов (например, разрешить символ *) и длину строки.
/^[a-z0-9_-]{3,16}$/
JS:
re.test('normal_login-123'); // true
re.test('IncorrectLogin'); // false
re.test('inc*rrect_l*gin'); // false
Что используем:
Символы ^ и $ указывают на начало и конец строки, так что введенный юзернейм будет проверен на совпадение полностью от первого до последнего символа.
2. Валидация email
Проверка адреса электронной почты на корректность – одна из самых частых задач веб-разработчика. Без этого не обходятся ни разнообразные формы подписки, ни авторизация.
Для валидации email существует множество различных регулярок. Вот одна из них – не самая большая и не самая сложная, но достаточно точная для быстрой проверки адреса:
/^[A-Z0-9._%+-]+@[A-Z0-9-]+.+.[A-Z]{2,4}$/i
JS:
re.test('correct-email@mail.com'); // true
re.test('CORRECT.email@mail123.com'); //true
re.test('incorrect-email@mail'); //false
Что используем:
Флаг i в регулярных выражений обеспечивает регистронезависимость сравнения.
3. Номер телефона
Проверяя номер телефона, обязательно учитывайте общепринятые форматы, так как в разных странах их принято записывать по-разному. Например, для американского стиля подойдет вот такая регулярка:
/^+?(d{1,3})?[- .]?(?(?:d{2,3}))?[- .]?ddd[- .]?dddd$/
JS:
re.test('(212) 348-2626'); // true
re.test('+1 832-393-1000'); // true
re.test('+1 202-456-11-11'); // false
Что используем:
Квантификатор ? соответствует одному предыдущему символу или его отсутствию.
4. Надёжность пароля
Часто встречаете на различных сервисах требование придумать сложный пароль? Кто и как определяет требуемую степень сложности? На самом деле, для этого есть некоторые стандарты: минимальная длина, разный регистр символов, наличие букв, цифр и специальных знаков.
Чтобы обеспечить ваших пользователей надежными паролями, можете воспользоваться вот таким выражением (или составить собственные регулярки со специфическими требованиями):
/^(?=.*[A-Z].*[A-Z])(?=.*[!@#$&*])(?=.*[0-9].*[0-9])(?=.*[a-z].*[a-z].*[a-z]).{8,}$/
JS:
re.test('qwerty'); // false
re.test('qwertyuiop'); // false
re.test('abcABC123$'); // true
Что используем:
Оператор ?= внутри скобочной группы позволяет искать совпадения «просматривая вперед» переданную строку и не включать найденный фрагмент в результирующий массив.
Подробнее о надежности паролей вы можете узнать из этого руководства.
5. Почтовый индекс (zip-code)
Формат почтового индекса, как и телефона, зависит от конкретного государства.
В России все просто: шесть цифр подряд без разделителей.
/^d{6}$/
Американский zip-code может состоять из 5 символов или в расширенном формате ZIP+4 – из 9.
/^d{5}(?:[-s]d{4})?$/
JS:
re.test('75457'); // true
re.test('98765-4321'); // true
Что используем:
Последовательность ?: внутри скобочной группы исключает ее из запоминания.
6. Номер кредитной карты
Разумеется, при проверке номера платежной карты не стоит полагаться на регулярные выражения. Однако с их помощью вы можете сразу же отсеять очевидно неподходящие последовательности и не нагружать сервер лишним запросом.
С помощью вот такой длинной регулярки вы можете поддерживать сразу несколько платежных систем:
/^(?:4[0-9]{12}(?:[0-9]{3})?|5[1-5][0-9]{14}|6(?:011|5[0-9][0-9])[0-9]{12}|3[47][0-9]{13}|3(?:0[0-5]|[68][0-9])[0-9]{11}|(?:2131|1800|35d{3})d{11})$/
Подробнее разобраться, откуда что взялось, вы можете здесь.
Что используем:
Вертикальная черта | в регулярных выражениях обозначает альтернацию, то есть выбор одного варианта из нескольких.
Распространенные форматы
7. Начальные и конечные пробелы
Пробелы в начале и конце строки обычно не несут никакой смысловой нагрузки, но могут повлиять на анализ и обработку данных, поэтому от них следует сразу же избавляться.
/^[ s]+|[ s]+$/g
JS:
let str = " hello "; console.log(str.length); // 7 str = str.replace(re, ''); console.log(str.length); // 5
Что используем:
Квантификатор + соответствует инструкции {1,} – один и более символов.
8. Дата
С датами приходится работать очень часто, а форматов записи у них великое множество. Прежде чем начинать обработку, имеет смысл проверить, соответствует ли вид переданной строки требуемому.
Вот такое регулярное выражение поддерживает несколько форматов дат – с полными и краткими числами (5-1-91 и 05-01-1991) и разными разделителями (точка, прямой или обратный слеш).
/^(?:(?:31(/|-|.)(?:0?[13578]|1[02]))1|(?:(?:29|30)(/|-|.)(?:0?[1,3-9]|1[0-2])2))(?:(?:1[6-9]|[2-9]d)?d{2})$|^(?:29(/|-|.)0?23(?:(?:(?:1[6-9]|[2-9]d)?(?:0[48]|[2468][048]|[13579][26])|(?:(?:16|[2468][048]|[3579][26])00))))$|^(?:0?[1-9]|1d|2[0-8])(/|-|.)(?:(?:0?[1-9])|(?:1[0-2]))4(?:(?:1[6-9]|[2-9]d)?d{2})$/
Здесь учитываются даже високосные годы!
JS:
re.test('29-02-2000'); // true
re.test('29-02-2001'); // false
Что используем:
Последовательности вида 1, 2 и так далее – это обратные ссылки на скобочные группы, определяющие вид разделителя. Благодаря им можно отсеять даты с разными разделителями:
re.test('10-10/2010'); // false
9. IPv4
Адрес IP используется для идентификации конкретного компьютера в интернете Он состоит из четырех групп цифр (байтов), разделенных точками (192.0.2.235).
/b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)b/
Что используем:
Класс b означает «границу слова» и имеет нулевую ширину (то есть это не отдельный символ).
10. IPv6
IPv6 – это новый, более сложный синтаксис IP-протокола. Выражение для проверки на этот формат выглядит куда страшнее, хотя на самом деле разница заключается только в поддержке шестнадцатеричных чисел:
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]).){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]).){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
11. Base64
Base64 – достаточно распространенный формат кодирования бинарных данных, который часто используется, например, в email-рассылках.
Для валидации строки в этом формате можно использовать следующее регулярное выражение:
^(?:[A-Za-z0-9+/]{4})*(?:[A-Za-z0-9+/]{2}==|[A-Za-z0-9+/]{3}=)?$
12. ISBN
ISBN – международная номенклатура для печатных книг. Номер может состоять из 10 (ISBN-10) или 13 цифр (ISBN-13). На самих книгах ISBN обычно разделен дефисами на несколько групп (код страны, издательства и самой книги), но для проверки и использования их следует удалять.
Это регулярное выражение позволяет проверить оба формата сразу:
/b(?:ISBN(?:: ?| ))?((?:97[89])?d{9}[dx])b/i
JS:
re.test('ISBN 9781106998966'); // true
re.test('1106998966'); // true
re.test('110699896x'); // true
Числа
13. Проверка на число
Очень простая проверка строки на число с помощью регулярок:
/^d{1,}$/
JS:
re.test('13'); // true
re.test('23yy'); // false
14. Разделитель разрядов
Задача разбить большое число на разряды по три цифры встречается в разработке довольно часто. Оказывается это очень легко сделать с помощью регулярок.
/d{1,3}(?=(d{3})+(?!d))/g
JS:
'1234567890'.replace(re, '$&,'); // 1,234,567,890
Что используем:
Комбинация $& в строке замены позволяет подставить найденную комбинацию.
15. Цена
Цены могут быть представлены во множестве различных форматов. Универсального регулярного выражения для них, скорее всего, не существует, но цену в долларах из строки извлечь очень просто.
Эта регулярка предполагает, что для разделения разрядов числа используются запятые, а дробная часть отделена точкой:
/($[0-9,]+(.[0-9]{2})?)/
JS:
let price = 'price $5,555.55'.match(re)[0]; '$5,555.55
Что используем:
Комбинация {2} означает, что символ из диапазона [0-9] должен быть повторен ровно 2 раза (дробная часть цены).
Файлы и URL
16. Сопоставить строку URL
Если вам необходимо проверить, является ли полученная строка URL-адресом, вы можете воспользоваться вот такой регуляркой:
/[-a-zA-Z0-9@:%_+.~#?&/=]{2,256}.[a-z]{2,4}b(/[-a-zA-Z0-9@:%_+.~#?&/=]*)?/gi
Она подойдет для адресов с различными протоколами (HTTP, HTTPS, FTP) и даже без протокола.
JS:
re.test('https://yandex.ru'); // true
re.test('yandex.ru'); // true
re.test('hello world'); // false
17. Извлечение домена
В URL-адресе много частей: протокол, домен, поддомены, путь к странице и строка запроса. С помощью регулярок можно отбросить все лишнее и получить только домен:
/https?://(?:[-w]+.)?([-w]+).w+(?:.w+)?/?.*/i
JS:
let domain = 'https://proglib.io'.match(re); console.log(domain[1]); // proglib
Что используем:
Метод match возвращает объект с данными совпадения. Под индексом 1 в нем хранится совпадение, соответствующее первой скобочной группе.
18. Расширения
Одна строчка регулярного выражения позволяет быстро и просто получить расширение файла, с которым вам предстоит работать:
/^(?:.*.(?=(htm|html|class|js)$))?[^.]*$/i
JS:
let file1 = 'script.js'.match(re)[1]; // js let file2 = 'hello'.match(re) [1]; // undefined
Разумеется, при необходимости сюда можно добавлять другие расширения.
19. Протокол
Иногда требуется извлечь протокол полученной ссылки. Регулярные выражения и тут облегчают жизнь:
/^([a-zA-Z]+):///
JS:
let protocol = 'https://proglib.io/'.match(re)[0]; // https
Социальные сети
20. Twitter
Имя пользователя Twitter:
/@([A-Za-z0-9_]{1,15})/
21. Facebook
URL аккаунта на Facebook:
/(?:http://)?(?:www.)?facebook.com/(?:(?:w)*#!/)?(?:pages/)?(?:[w-]*/)*([w-]*)/
22. YouTube
Получение ID видео на YouTube:
/https://(?:youtu.be/|(?:[a-z]{2,3}.)?youtube.com/watch(?:?|#!)v=)([w-]{11}).*/gi
JS:
re.exec('https://www.youtube.com/watch?v=JbgvaQ_rM4I')[1]; // JbgvaQ_rM4I
Что используем:
Метод exec объекта регулярного выражения работает почти так же, как метод match строки.
HTML и CSS
23. HEX-цвета
Веб-разработчику часто приходится иметь дело с цветами, заданными в шестнадцатеричном формате. Регулярки позволяют легко извлекать такие цвета из строки:
/#([a-fA-F]|[0-9]){3, 6}/
Крутой рецепт, правда? 
24. Адрес изображения
Для получения адреса изображения обычно используется DOM-метод img.getAttribute('src'). Регулярки для этого применяются редко, но полезно все же знать их возможности:
/< *[img][^>]*[src] *= *["']{0,1}([^"' >]*)/
JS:
re.exec('<img src="image.png" alt="image1">')[1]; // image.png
25. CSS-свойства
Еще одна нетривиальная ситуация – получение свойств CSS с помощью регулярных выражений:
/s*[a-zA-Z-]+s*[:]{1}s[a-zA-Z0-9s.#]+[;]{1}/gm
JS:
let css = ` .element {
color: white;
background: black;
font-size: 16px;
}`
css.match(re);
Что используем:
Флаг m в регулярных выражениях включает многострочный режим.
26. HTML комментарии
А это очень полезная регулярка для удаления комментариев из HTML-кода:
/<!--(.*?)-->/
Что используем?
Символ ?, стоящий в регулярном выражении после другого квантификатора, переводит его в ленивый режим.
27. Title
Получить заголовок веб-страницы можно с помощью такого регулярного выражения:
/<title>([^<>]*?)</title>/
28. rel=«nofollow»
Важная SEO-задача, которую очень не хочется делать вручную, – добавление внешним ссылкам атрибута rel="nofollow". Обратимся к регулярным выражениям:
PHP:
$html = '<a href="https://site.com">site.com</a>, <a href="my-site.com">my-site.com</a>, <a href="https://site.com" rel="nofollow">site.com</a>'; $re = '/(<as*(?![^>]*brel=)([^>]*bhref="https?://[^"]+"))/'; $result = preg_replace($re, '$1 rel="nofollow"', $html);
Эта регулярка выбирает в тексте все ссылки с протоколом http/https без атрибута rel и добавляет его.
29. Медиа запросы
Если требуется проанализировать медиа-запросы CSS, воспользуйтесь этой регуляркой:
/@media([^{]+){([sS]+?})s*}/g
Что используем:
Класс s обозначает пробельный символ (а также таб и перевод строки), а класс S – наоборот, любой символ кроме пробельного.
30. Подсветка слов
Полезное выражение для поиска и выделения слов в тексте:
/b(ipsum)b/ig
JS:
let text = 'Lorem ipsum dolor, lorem ipsum dolor.'; text.replace(re, '<span style="background: yellow">$&</span>')
PHP:
$re = '/b(ipsum)b/i'; $text = 'Lorem ipsum dolor, lorem ipsum dolor.'; preg_replace($re, '<span style="background:#5fc9f6">1</span>', $text);
Разумеется, слово ipsum можно заменить на любое другое слово или словосочетание
Другие задачи веб-разработчика
31. Проверка версии Internet Explorer
К счастью, старый добрый IE постепенно уходит в прошлое, но он все же еще играет некоторую роль в современном вебе. Этот фрагмент кода позволяет определить версию всеми любимого браузера:
/^.*MSIE [5-8](?:.[0-9]+)?(?!.*Trident/[5-9].0).*$/
32. Удалить повторы
Регулярки дают возможность автоматически удалить случайные повторы слов без проглядывания всего текста:
/(w+)s+1/gi
JS:
"hello world world hello".replace(re, "$1") // hello world hello
33. Количество слов
Порой веб-разработчику необходимо определить количество слов в строке, например, для организации ключевых слов в инструментах аналитики. Сделать это можно с помощью следующих регулярок:
^[^s]*$ // ровно одно слово
^[^s]*s[^s]*$ // ровно два слова
^[^s]*s[^s]* // два слова и больше
^([^s]*s){2}[^s]*$ // ровно три слова
^([^s]*s){4, }[^s]*$ // пять слов и больше
Свои любимые регулярки пишите в комментариях 
Полезные статьи по регулярным выражениям
- 5 практических примеров использования регулярных выражений на JavaScript
- Практическое введение в регулярные выражения для новичков
- 11 материалов по регулярным выражениям
- Регулярные выражения: 5 сервисов для тестирования и отладки
Такая элементарная вещь, как номер телефона, в письменных текстах живёт во множестве вариантов. Обыкновенный номер типа +7 (123) 123-45-67 можно встретить записанным без скобок или дефисов (+7 123 1234567), а то и вообще без пробелов (+71231234567). Не собираюсь оскорблять чувства пишущих, им и так непросто. Но уважающий себя веб-ресурс не может допустить такой типографической разношёрстности. Плюс к тому, необлагороженные номера неудобно читать человеку (то самое human-readable).
Данная статья о том, как привести все телефонные номера на странице к однообразному виду, а также проставить корректные ссылки типа tel: на них. Для решения поставленной задачи используются регулярные выражения JavaScript. Хороший обзор регэкспов дан здесь, также почитать по теме можно на MDN.
В качестве эталонной будет принята запись номера вида +7 (123) 123-45-67.
Найти все телефонные номера на странице можно таким способом:
let pattern = new RegExp('(+7|8)[s(]*d{3}[)s]*d{3}[s-]?d{2}[s-]?d{2}', 'g'); // создать регулярное выражениеlet phoneNumbers = document.body.innerText.match(pattern); // применить на всём тексте документа
Метод match() вернёт и запишет в переменную phoneNumbers массив (объект типа Array) со всеми найденными на странице номерами.
Дисклеймер. Виденное выше регулярное выражение может вызвать сильное чувство боли в глазах у неподготовленного читателя. Если вы не очень знакомы с регулярками, автор всё-таки советует для начала проработать несколько первых глав учебника на LearnJavascript.
Разберём это выражение:
(+7|8) |
+7 (123) 123-45-67
На практике встречается начало и с
Напомню: |
[s(]*d{3}[)s]* |
+7 (123) 123-45-67 |
[s(]* |
+7 (123) 123-45-67
То есть, фактически, эти части паттерна распознают первые три цифры после кода страны, причём как взятые в скобки, так и без (квантификатор
Также напомню: |
d{3}[s-]?d{2}[s-]?d{2} |
+7 (123) 123-45-67 |
[s-]? |
+7 (123) 123—45—67
Данная часть паттерна распознаёт последние 7 цифр номера. Они могут быть разделены дефисами, пробелами или вообще ничем.
Наверное, уже нет смысла пояснять, что цифра, взятая в фигурные скобки |
Ну хорошо, найти все номера получилось. К сожалению, задача этим не исчерпывается. Как же взять и заменить все вхождения разом?
Здесь поможет метод replace(). Если у регулярного выражения указан флаг 'g' (второй аргумент конструктора), то replace() заменит все вхождения на то, что указано. Например, задача замены всех повторяющихся пробелов в тексте на одинарные решается таким простым способом:
text = text.replace(/s{1,}/g, ' ');
На всякий: /s{1,}/g — это краткая запись для new RegExp('s+', 'g'). Также вместо {1,} можно писать просто +.
Но ведь у нас задача сложнее: нельзя же заменить разные номера телефонов на один! Тут самое время вспомнить о скобочных группах.
Скобочная группа — термин из теории регулярных выражений. Технически это просто часть паттерна, взятая в скобки. Но к любой такой группе можно обратиться по индексу.
Получается,
К счастью, replace() поддерживает работу с группами. Достаточно написать в шаблоне замены (второй параметр) ${номер_группы} ($1 или $5), и функция заменит эту конструкцию на содержимое скобочной группы.
То была идея, а теперь реализация:
let pattern = /(+7|8)[s(]?(d{3})[s)]?(d{3})[s-]?(d{2})[s-]?(d{2})/g; // паттерн с проставленными скобкамиlet phoneNumbers = document.body.innerText.match(pattern); // найдём все номераlet correctNumber = phoneNumbers[0].replace(pattern, '+7 ($2) $3-$4-$5'); // пробуем заменуconsole.log(correctNumber);
В результате будет выведен аккуратный, каноничный телефонный номер. Работает!
Теперь, чтобы заменить все найденные номера телефонов на единообразные, добавим флаг g:
let pattern = /(+7|8)[s(]?(d{3})[s)]?(d{3})[s-]?(d{2})[s-]?(d{2})/g;document.body.innerHTML = document.body.innerHTML.replace(pattern, '+7 ($2) $3-$4-$5');
Усложним шаблон функции replace(), чтобы номер телефона был кликабельным (ссылка с префиксом tel:):
let pattern = /(+7|8)[s(]?(d{3})[s)]?(d{3})[s-]?(d{2})[s-]?(d{2})/g;document.body.innerHTML = document.body.innerHTML.replace(pattern, '<a href="tel:+7$2$3$4$5">+7 ($2) $3-$4-$5</a>');
То есть, для корректной работы ссылки нужно в её коде выписать все цифры номера подряд — как раз самый неудобный для чтения человеком вариант.
Without knowing what language you’re using I am unsure whether or not the syntax is correct.
This should match all of your groups with very few false positives:
/(?([0-9]{3}))?([ .-]?)([0-9]{3})2([0-9]{4})/
The groups you will be interested in after the match are groups 1, 3, and 4. Group 2 exists only to make sure the first and second separator characters , ., or - are the same.
For example a sed command to strip the characters and leave phone numbers in the form 123456789:
sed "s/({0,1}([0-9]{3})){0,1}([ .-]{0,1})([0-9]{3})2([0-9]{4})/134/"
Here are the false positives of my expression:
- (123)456789
- (123456789
- (123 456 789
- (123.456.789
- (123-456-789
- 123)456789
- 123) 456 789
- 123).456.789
- 123)-456-789
Breaking up the expression into two parts, one that matches with parenthesis and one that does not will eliminate all of these false positives except for the first one:
/(([0-9]{3}))([ .-]?)([0-9]{3})2([0-9]{4})|([0-9]{3})([ .-]?)([0-9]{3})5([0-9]{4})/
Groups 1, 3, and 4 or 5, 7, and 8 would matter in this case.
Without knowing what language you’re using I am unsure whether or not the syntax is correct.
This should match all of your groups with very few false positives:
/(?([0-9]{3}))?([ .-]?)([0-9]{3})2([0-9]{4})/
The groups you will be interested in after the match are groups 1, 3, and 4. Group 2 exists only to make sure the first and second separator characters , ., or - are the same.
For example a sed command to strip the characters and leave phone numbers in the form 123456789:
sed "s/({0,1}([0-9]{3})){0,1}([ .-]{0,1})([0-9]{3})2([0-9]{4})/134/"
Here are the false positives of my expression:
- (123)456789
- (123456789
- (123 456 789
- (123.456.789
- (123-456-789
- 123)456789
- 123) 456 789
- 123).456.789
- 123)-456-789
Breaking up the expression into two parts, one that matches with parenthesis and one that does not will eliminate all of these false positives except for the first one:
/(([0-9]{3}))([ .-]?)([0-9]{3})2([0-9]{4})|([0-9]{3})([ .-]?)([0-9]{3})5([0-9]{4})/
Groups 1, 3, and 4 or 5, 7, and 8 would matter in this case.