Проверка данных регулярными выражениями
Сборник регулярных выражений с примерами на PHP для проверки данных из полей форм.
1
Проверка чисел
$text = '1';
if (preg_match("/^d+$/", $text)) {
echo 'yes';
} else {
echo 'no';
}PHP
Числа с плавающей точкой (разделитель точка):
$text = '-1.0';
if (preg_match("/^-?d+(.d{0,})?$/", $text)) {
echo 'yes';
} else {
echo 'no';
}PHP
2
Проверка даты по формату
Формат DD.MM.YYYY
$text = '02.12.2018';
if (preg_match("/^(0[1-9]|[12][0-9]|3[01])[.](0[1-9]|1[012])[.](19|20)dd$/", $text)) {
echo 'yes';
} else {
echo 'no';
}PHP
Формат MySQL YYYY-MM-DD
$text = '2018-04-02';
if (preg_match("/^[0-9]{4}-(0[1-9]|1[012])-(0[1-9]|1[0-9]|2[0-9]|3[01])$/", $text)) {
echo 'yes';
} else {
echo 'no';
}PHP
3
Проверка номера телефона
Ориентировано на российские мобильные + городские с кодом из 3 цифр.
$text = '+7(495)000-00-00';
if (preg_match("/^((8|+7)[- ]?)?((?d{3})?[- ]?)?[d- ]{7,10}$/", $text)) {
echo 'yes';
} else {
echo 'no';
}PHP
4
Проверка E-mail
$text = 'mail@snipp.ru';
if (preg_match("/^([a-z0-9_-]+.)*[a-z0-9_-]+@[a-z0-9_-]+(.[a-z0-9_-]+)*.[a-z]{2,6}$/i", $text)) {
echo 'yes';
} else {
echo 'no';
}PHP
5
Логин
Латинские буквы, цифры, - и _.
$text = 'admin-1';
if (preg_match("/^[a-z0-9_-]{2,20}$/i", $text)) {
echo 'yes';
} else {
echo 'no';
}PHP
6
Проверка md5-хэша
$text = 'ca040cb5d6c2ba8909417ef6b8810e2e';
if (preg_match("/^[a-f0-9]{32}$/", $text)) {
echo 'yes';
} else {
echo 'no';
}PHP
7
Цвета
Шестнадцатеричные коды цветов #FFF и #FFFFFF.
$text = '#fff';
if (preg_match("/^#(?:(?:[a-fd]{3}){1,2})$/i", $text)) {
echo 'yes';
} else {
echo 'no';
}PHP
8
IP адреса
IPv4 адрес:
$text = '192.168.0.1';
if (preg_match("/^((25[0-5]|2[0-4]d|[01]?dd?).){3}(25[0-5]|2[0-4]d|[01]?dd?)$/", $text)) {
echo 'yes';
} else {
echo 'no';
}PHP
IPv6 адрес:
$text = '2001:DB8:3C4D:7777:260:3EFF:FE15:9501';
if (preg_match("/((^|:)([0-9a-fA-F]{0,4})){1,8}$/i", $text)) {
echo 'yes';
} else {
echo 'no';
}PHP
14.06.2018, обновлено 21.12.2022
Другие публикации
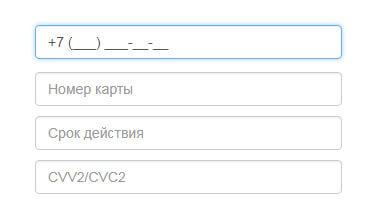
Применение масок ввода у полей форм значительно упрощает их использование, уменьшает количество ошибок и приводит…

date($format, $timestamp) – форматирует дату/время по шаблону, где…

Несколько примеров, как сгенерировать случайные последовательности численных и буквенных строк заданной длины и…

Протокол FTP – предназначен для передачи файлов на удаленный хост. В PHP функции для работы с FTP как правило всегда доступны и не требуется установка дополнительного расширения.

В следующей таблице приведены имена констант (VK Codes), десятичные и шестнадцатеричные значения для кодов виртуальных…

В статье приведен пример формы и php-скрипта для безопасной загрузки файлов на сервер, возможные ошибки и рекомендации при работе с данной темой.
This is another question about a previous question I had asked yesterday. I want user to be allowed to type US phone numbers in the following formats.
(800)-555-1212
800-555-1212
and have it only check the database for numbers 8005551212
I’ve seen that regex like
/^[+]?([0-9]*)s*(?s*([0-9]{3})?s*)?[s-.]*([0-9]{3})[s-.]*([0-9]{4})[a-zA-Zs,.]*[x#]*[a-zA-Z.s]*([d]*)/
may work but I’m not certain how to implement it into the code from the link I provided
I’m new to php and know nothing about regex. Any help is appreciated.
![]()
asked Aug 8, 2013 at 7:01
![]()
6
This function validate a phone number, return true if it validate and false if invalid. This function very simple i was wrote to.
/**
* @param $number
*
* @return bool
*/
function validatePhoneNumber($number) {
$formats = [
'###-###-####', '####-###-###',
'(###) ###-###', '####-####-####',
'##-###-####-####', '####-####', '###-###-###',
'#####-###-###', '##########', '#########',
'# ### #####', '#-### #####'
];
return in_array(
trim(preg_replace('/[0-9]/', '#', $number)),
$formats
);
}
answered Aug 8, 2013 at 7:10
![]()
4
if javascript is ok can go with
<script type="text/javascript">
function matchClick() {
var re = new RegExp("Your regex here");
if (document.formname.phone.value.match(re)) {
alert("Ok");
return true;
} else {
alert("Not ok");
return false;
}
}
</script>
call this function onsubmit of form or onblur of textbox
If you have doubt about your regex you can validate it at http://www.regular-expressions.info/javascriptexample.html
answered Aug 8, 2013 at 7:10
![]()
user2408578user2408578
4641 gold badge4 silver badges13 bronze badges
You can use this pattern
(?d{3,3})?-d{3,3}-d{4,4}
answered Aug 8, 2013 at 7:10
![]()
Taleh IbrahimliTaleh Ibrahimli
7504 gold badges13 silver badges29 bronze badges
Try this,
<?php
$t='/(?[2-9][0-8][0-9])?[-. ]?[0-9]{3}[-. ]?[0-9]{4}/';
$arr=preg_match($t,'(800)-555-1212',$mat);
$arr=preg_match($t,'800-555-1212',$mat);
print_r($mat);
?>
Tested here
answered Aug 8, 2013 at 7:57
![]()
Rohan KumarRohan Kumar
40.2k11 gold badges75 silver badges105 bronze badges
1
Re: Rohan Kumar’s solution
<?php
$t='/(?[2-9][0-8][0-9])?[-. ]?[0-9]{3}[-. ]?[0-9]{4}/';
$arr=preg_match($t,'(800)-555-1212',$mat);
$arr=preg_match($t,'800-555-1212',$mat);
print_r($mat);
?>
It does address the issue of fake phone numbers such as 800-123-2222. Real phone numbers have a first digit of at least «2». While the other solutions do the format correctly, they don’t address the issue of people putting in phone numbers like 800-000-1234, which would be correct in the other solutions provided.
answered Jan 8, 2014 at 15:30
![]()
Сборник основных шаблонов регулярных выражений на PHP для проверки данных.
Проверка набора из латинских букв и цифр
Регулярное выражение для проверки набора только из латинских букв и цифр:
$pattern = '/^[a-z0-9]+$/i';
$var = 'String123';
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}Если необходимо добавить в набор некоторые символы:
// использовать тире
$pattern = '/^[a-z0-9-]+$/i';
$var = 'String-123';
// использовать знак подчёркивания
$pattern = '/^[a-z0-9-_]+$/i';
$var = 'String-1_23';
// использовать точку
$pattern = '/^[a-z0-9-_.]+$/i';
$var = 'String-1_23.end';
// использовать пробел
$pattern = '/^[a-z0-9-_. ]+$/i';
$var = 'String-1_23.end ps...';Проверка на кириллицу и цифры
Регулярное выражение для проверки набора только из букв кириллицы и цифр:
$pattern = '/^[а-яё0-9]+$/iu';
$var = 'Строка123';
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}Проверка на число
Регулярное выражение для проверки данных на целое число:
$pattern = '/^d+$/';
// Исключаем 0
$pattern = '/^[1-9]+$/';
// Не больше 1-й цифры
$pattern = '/^[1-9]{1}+$/';
// Максимум 4 цифры
$pattern = '/^[1-9]{1,4}+$/';
$var = 123;
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}Регулярное выражение для проверки данных на тип Float (числа с плавающей точкой):
$pattern = '/^[0-9]*[.,][0-9]+$/';
$var = 123.45;
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}
// Если нужно, чтобы пропускал и целые числа
$pattern = '/^[0-9]*[.,]?[0-9]+$/';Проверка логина
Регулярное выражение для проверки логина. Разрешено использовать только латинские буквы, цифры, тире и знак подчёркивания. Длина логина от 2 до 20 символов (включительно):
$text = 'Login_123-45';
if (preg_match("/^[a-z0-9-_]{2,20}$/i", $text)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}Проверка Email
Регулярное выражение для проверки Email:
$pattern = '/^([a-z0-9_-]+.)*[a-z0-9_-]+@[a-z0-9_-]+(.[a-z0-9_-]+)*.[a-z]{2,6}$/';
$var = 'admin@site.com';
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}Более современный и правильный способ:
$var = 'admin@___site.com';
$email = filter_var($var, FILTER_SANITIZE_EMAIL);
if (!filter_var($email, FILTER_VALIDATE_EMAIL))
throw new InvalidArgumentException('Invalid Email');
return $email;Проверка номера телефона
Регулярное выражение для проверки номера телефона:
$pattern = '/^((8|+7)[- ]?)?((?d{3})?[- ]?)?[d- ]{7,10}$/';
$var = '+7(982)000-00-00';
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}Проверка даты по формату
Формат DD.MM.YYYY:
$pattern = '/^(0[1-9]|[12][0-9]|3[01])[.](0[1-9]|1[012])[.](19|20)dd$/';
$var = '10.12.2019';
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}Формат MySQL YYYY-MM-DD:
$pattern = '/^[0-9]{4}-(0[1-9]|1[012])-(0[1-9]|1[0-9]|2[0-9]|3[01])$/';
$var = '2019-12-10';
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}Проверка md5-хэша
Регулярное выражение для проверки на корректность md5-хэша:
$pattern = '/^[a-f0-9]{32}$/';
$var = '341be97d9aff90c9978347f66f945e77';
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}Проверка IP адресов
Регулярное выражение для проверки IPv4 адреса:
$pattern = '/^((25[0-5]|2[0-4]d|[01]?dd?).){3}(25[0-5]|2[0-4]d|[01]?dd?)$/';
$var = '192.168.0.1';
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}Проверка IPv6 адреса:
$pattern = '/((^|:)([0-9a-fA-F]{0,4})){1,8}$/i';
$var = '2001:DB8:3C4D:7777:260:3EFF:FE15:9501';
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}Проверка доменного имени
Регулярное выражение для проверки на корректность доменного имени сайта:
$pattern = '/^(https?://)?([da-z.-]+).([a-z.]{2,6})([/w .-]*)*/?$/';
$var = 'https://prowebmastering.ru';
if (preg_match($pattern, $var)) {
echo 'Проверка пройдена успешно!';
} else {
echo 'Проверка не пройдена!';
}In this short tutorial, we’re going to look at validating a phone number in PHP. Phone numbers come in many formats depending on the locale of the user. To cater for international users, we’ll have to validate against many different formats.
In this article
- Validating for Digits Only
- Checking for Special Characters
- International Format
- Key Takeaways
- 10 minute read
Validating for Digits Only
Let’s start with a basic PHP function to validate whether our input telephone number is digits only. We can then use our isDigits function to further refine our phone number validation.
We use the PHP preg_match function to validate the given telephone number using the regular expression:
/^[0-9]{'.$minDigits.','.$maxDigits.'}z/
This regular expression checks that the string $s parameter only contains digits [0-9] and has a minimum length $minDigits and a maximum length $maxDigits. You can find detailed information about the preg_match function in the PHP manual.
Checking for Special Characters
Next, we can check for special characters to cater for telephone numbers containing periods, spaces, hyphens and brackets .-(). This will cater for telephone numbers like:
- (012) 345 6789
- 987-654-3210
- 012.345.6789
- 987 654 3210
The function isValidTelephoneNumber removes the special characters .-() then checks if we are left with digits only that has a minimum and maximum count of digits.
International Format
Our final validation is to cater for phone numbers in international format. We’ll update our isValidTelephoneNumber function to look for the + symbol. Our updated function will cater for numbers like:
- +012 345 6789
- +987-654-3210
- +012.345.6789
- +987 654 3210
The regular expression:
/^[+][0-9]/
tests whether the given telephone number starts with + and is followed by any digit [0-9]. If it passes that condition, we remove the + symbol and continue with the function as before.
Our final step is to normalize our telephone numbers so we can save all of them in the same format.
Key Takeaways
- Our code validates telephone numbers is various formats: numbers with spaces, hyphens and dots. We also considered numbers in international format.
- The validation code is lenient i.e: numbers with extra punctuation like 012.345-6789 will pass validation.
- Our normalize function removes extra punctuation but wont add a + symbol to our number if it doesn’t have it.
- You could update the validation function to be strict and update the normalize function to add the + symbol if desired.
Описание регулярных выражений
Получить расширение файла
echo preg_replace("/.*?./", '', 'photo.jpg');
Результат работы примера:
jpg
Взять то, что находится между тегами <title> и </title>
<?
if (preg_match('|<title[^>]*?>(.*?)</title>|si', $str, $arr)) $title = $arr[1];
else $title='';
?> Обратите внимание: берется не нулевой элемент массива, а первый!
Если title будет встречаться несколько раз, то будет вырезан первый!
Найти текст, заключенный в какой-то тег и заменить его на другой тег
Например: <TITLE> … </TITLE> заменить аналогично на <МОЙ_ТЕГ> … </МОЙ_ТЕГ> в HTML-файле:
echo preg_replace("!<title>(.*?)</title>!si","<МОЙ_ТЕГ>\1</МОЙ_ТЕГ>",$string);
Проверяем, является ли переменная числом
if (!preg_match("|^[d]+$|", $var)) ...
Запретим пользователю использовать в своем имени любые символы, кроме букв русского и латинского алфавита, знака «_» (подчерк), пробела и цифр:
if (preg_match("/[^(w)|(x7F-xFF)|(s)]/",$username)) {
echo "invalid username";
exit;
}
Проверка адреса e-mail
Для поля ввода адреса e-mail добавим в список разрешенных символов знаки «@» и «.» и «-«,
иначе пользователь не сможет корректно ввести адрес. Зато уберем русские буквы и пробел:
if (preg_match("/[^(w)|(@)|(.)|(-)]/",$usermail)) {
echo "invalid mail";
exit;
}
Проверка на число
if(preg_match('/^d+$/', $var)) echo $var;
Проверка имени файла
if (preg_match("/(^[a-zA-Z0-9]+([a-zA-Z_0-9.-]*))$/" , $filename)==NULL) {
echo "invalid filename";
exit;
}
Проверка расширения файла
Архивы (zip, rar, …)
/.(?:z(?:ip|[0-9]{2})|r(?:ar|[0-9]{2})|jar|bz2|gz|tar|rpm)$/i
Аудио (mp3, wav, …)
/.(?:mp3|wav|og(?:g|a)|flac|midi?|rm|aac|wma|mka|ape)$/i
Программы (exe, xpi, …)
/.(?:exe|msi|dmg|bin|xpi|iso)$/i
Изображения (jpg, png, …)
/.(?:jp(?:e?g|e|2)|gif|png|tiff?|bmp|ico)$/i
Видео (mpeg, avi, …)
/.(?:mpeg|ra?m|avi|mp(?:g|e|4)|mov|divx|asf|qt|wmv|mdv|rv|vob|asx|ogm)$/i
Выборка цен
Часто возникает проблема по парсингу интересующих программиста данных из HTML,
который не всегда хорошего качества, все было бы терпимо, если бы еще не вставки
на javascript’е, вот пример такого текста:
<TD>20.02<BR>05:30 <TD class=l>Товар 1<BR>Товар 2 <TD><B>35</B> <TD><A href="http://ссылка/" id=sfsd32dfs onclick="return m(this)">26.92</A><BR><A href="http://ссылка/" id=r3_3143svsfd onclick="return m(this)">27.05</A> <TD><B>270.5</B> </TR>
Те цифры, которые написаны через точку, являются ценами. Задача состоит в
том, чтобы собрать все цены, которые находятся между тегами <a>… </a> Видим,
что помимо цен между заданными тегами, есть такие, которые идут сразу после тега
<TD>, а также стоят между тегами <B>…</B>. Ясно, что описать достаточно точно
содержимое атрибутов тега <A> представляется задачей не самой легкой, поэтому
надо ее упростить! Любой тег имеет закрывающий знак ‘>’, наша задача описать,
что этот знак идет перед ценой, но так как перед ценой может стоять тег <B> и
тег <TD>, но эти цены нам не нужны. Каким образом мы узнаем, что цена стоит
между тегами <A>…</A>? По тегу, который идет после цены, если это не тег </B>,
то это будет либо тег </A> либо <BR>, а так же по тегу перед ценой если этот тег
<TD>. Путем таких размышлений мы пришли к выводу, что должно стоять справа, а
что должно стоять слева искомой строки, которая описывается как цифры,
разделенные точкой: d*.d* То, что должно совпасть слева, мы описали как
символ ‘>’, записываем: (?<=>) — выглядит немного странно, но совпадение справа
записывается вот так (?<=), а внтури него после ?<= идет символ ‘>’ То, что
должно совпасть справа описывается (?=) внутри мы пишем </A>. Теперь опишем,
что не должно стоять перед ценой: (?<!<TD>) перед ценой не должен стоять тег <TD>,
это и есть негативная ретроспективная проверка. При помощи негативной
опережающей проверки опишем, что не должно стоять справа цены: (?!</B>) справа
от цены не должен стоять тег </B>. Результирующее регулярное выражение, которое
описывает все приведенные условия выглядит вот так:
preg_match_all("/(?<!<TD>)(?<=>)d*.d*(?!</B>)(?=</A>)/", $string, $matches);
print_r($matches);
После рассмотрения первого примера стоит сделать замечания и пояснения по
поводу использования позиционных проверок.
1. Написанные друг за другом проверки применяются независимо друг от друга в
одной точке, не меняя ее. Естественно, что совпадение будет найдено, если все
проверки совпадут. В нашем примере это были точки перед и после цены. С точки
зрения логики применения проверок нет никакой разницы, будет ли стоять проверка
на тег <TD> перед проверкой на знак ‘>’. Правда, с точки зрения оптимизации
первой позиционной проверкой должна идти та, которая имеет наибольшую
вероятность несовпадения.
2. Совпавшие значения ретроспективных проверок не сохраняются. Т.е. если в
нашем примере совпадает опережающая проверка, которая указывает, что после цены
идет тег </A>, то сам тег </A>, который заключен в конструкцию (?=) не будет
запоминаться в специальных перменных /1,/2 и т.д. Сделано это из-за того, что
позиционная проверка совпадает не со строкой, а с местом в строке (она описывает
место, где произошло совпадение, а не символы, которые совпали).
3. Нужно указать что PCRE не позволяет делать проверки на совпадение текста
произвольной длинны. То есть нельзя делать, например, такую проверку: /(?<=d+)
Механизм поиска совпадения в ретроспективной проверке реализован так, что при
поиске механизму должна подаваться строка фиксированной длины, для того, чтобы в
случае несовпадения, механизм мог вернуться назад на фиксированое количество
символов и продолжить поиск совпадений в других позиционных проверках. Думаю,
что сразу это понять сложно, но представьте себе как происходит поиск совпадения
в части (?)(?<=>) вышеописанного регулярного выражения. Берется строка, в
которой происходит поиск, отсчитывается от начала столько символов, сколько
символов будет в совпадении позиционной проверки, в нашем варианте это 4: <, T,
D, > с этого места происходит «заглядывание назад» (ретроспективные проверки на
английском языке звучит как lookbhind assertions), т.е. все предыдущие 4 символа
проверяются на совпадение со строкой <TD>, если механизм не нашел совпадения, то
ему надо вернуться на 4 символа назад, выполнить тоже самое с проверкой (?<=>),
т.е. отсчитать один символ, «заглянуть» назад, попробовать найти проверку
предыдущего символа с символом ‘>’. Представьте себе, что условие совпадения
состоит из строки нефиксированной длинны: (??) подобная запись должна означать,
что перед ценой, не должен стоять тег <TD> в количестве максимимум один
экземпляр (либо вообще не стоять). Вот и получается, что после того, как
механизм отсчитает 4 символа от начала, он проверит на совпадение с <TD>, но в
условии указано, что тега может и не быть вообще, тогда возникает вопрос, на
сколько знаков верунться назад, чтобы проверить на совпадение другие проверки.
На 4 или вообще не возвращаться? Сразу возникает вопрос, а зачем идти вперед,
чтобы потом «заглянуть» назад? Делается это для того, чтобы в случае совпадения
всех проверок сразу же начать проверку тех символов, которые идут после
позиционных проверок.
Выбрать все изображения со страницы
Как-то мне нужно было получить все изображения, которые использовались на
сайте. Что для этого надо сделать? Правильно, надо в браузере нажать на
«Сохранить как», указать куда сохранить страницу. Появится файл с исходным кодом
страницы и папка с изображениями. Но вы никогда не сохраните в эту папку
изображения, которые прописаны в стилях объектов по крайней мере в эксплорере:
style="background-image:url(/editor/em/Unlink.gif);"
Для проведения вышеописанной операции надо:
1. попросить хозяина хоста использовать контент, размещенный на его сайте.
2. найти в тексте все строки, подобные приведенной выше, и выделить в них относительный путь к файлу
3. сформировать файл в котором будут выводиться изображения при помощи:
<img src=полный_путь_к_изображению>
Делаем: В переменную $content получаем исходный код страницы. А дальше используя
регулярные выражения ищем относительные пути, которые прописаны в стилях. Каждый
раз, когда я описываю, как я реализовал пример, я сначала тщательно описываю,
что ищем, и тщательно описываю, в каком контексте происходит поиск.
Проанализировав исходный код страницы стало понятно, что кроме как в описании
стилей относительные пути к изображениям нигде не используются. Слева от
относительного пути идет последовательность символов: url( Справа от
относительного пути стоит закрывающаяся круглая скобка. Между этими
последовательностями символов могут быть буквы латинского алфавита, цифры и
слеши, а также точка перед расширением файла.
Начнем с простого. Символы латинского алфавита, цифры, точка и слеш описываются символьным классом: [a-z./]
их может быть сколько угодно, на самом деле больше 3 (имя файла, минимум один
символ, точка, расширение, минимум один символ), но в данном случае, зная
контекст, это некритично, поэтому указываем квантификатор * [a-z./]* Слева
должны идти ‘url(‘ и мы это описываем при помощи позитивной ретроспективной
проверки: (?<=url() Но обратите внимание на то, что скобка в регулярных
выражениях является спецсимволом группировки, поэтому чтобы она стала символом,
надо перед ней поставить другой спецсимвол — слеш. (?<=url() Справа от
относительного пути должна стоять закрывающаяся круглая скобка. Это условие
описывается при помощи позитивной опережающей проверки: (?=)) Как видите, перед
одной из скобок стоит слеш, что означает, что она интепретируется не как
спецсимвол, а как литерал. Ниже приведен полный код на PHP, который выполняет
все действия, кроме вопроса о разрешении использовать контент:
preg_match_all("/(?<=url()[a-z./]*(?=))/i", $content, $matches);
foreach($matches[0] as $item)
{ echo "<img src = http://htmlweb.ru".$item.">"; }
Парсер всех внешних и внутренних ссылок со страницы
В массиве $vnut только ссылки внутренние, в массиве $vnech только внешние ссылки.
$html=file_get_contents ('http://www.popsu.net');
$url='popsu.net';
$vnut=[];
$vnech=[];
preg_match_all('~<a [^<>]*href=['"]([^'"]+)['"][^<>]*>(((?!~si',$html, $matches);
foreach ($matches[1] as $val) {
if (!preg_match("~^[^=]+://~", $val) || preg_match("~^[^://]+://(www.)?".$url."~i", $val)) { $vnut[]=$val; }
else $vnech[]=$val;
}
$vnut=array_unique ($vnut);
$vnech=array_unique ($vnech);
print_r ($vnut);
print_r ($vnech);Является ли строка числом, длиной до 77 цифр:
if (preg_match("/^[0-9]{1,77}$/",$string)) echo "ДА";
Состоит ли строка только из букв, цифр и «_», длиной от 8 до 20 символов:
if (preg_match("/^[a-zа-я0-9_]{8,20}$/",$string)) echo "yes"; else echo "no";
Проверка строки на допустимость
Есть ли в строке любые символы, кроме допустимых. Допустимыми считаются
буквы, цифры и «_». Длину тут проверять нельзя,
разве что просто дополнительным условием strlen($string). Не путайте с предыдущим
примером — хоть результат и одинаковый, но метод другой, «от противного»
if ( ! preg_match("/[^a-zа-я0-9_]/",$string))
echo "нет посторонних букв (OK)";
else
echo "есть посторонние буквы (FALSE)";
Для регистро независимого сравнения используйте preg_match с модификатором i().
Проверка повторяющихся символов
Есть ли в строке идущие подряд символы, не менее 3-х символов
подряд (типа «абвгДДДеё», но не «ааббаабб»):
if (preg_match("/(.)\1\1/",$string)) echo "yes"; else echo "no";
Заменить везде в тексте СТРОКУ1 на СТРОКУ2
(задача решается без регулярных выражений):
$string=str_replace("СТРОКА1","СТРОКА2",$string);
Заменить кривые коды перехода строки на нормальные:
для этого нужно только удалить «r». Переходы бывают нормальными (но разными!):
«n» или «rn». Еще бывают глюки, типа «rrn».
$string=str_replace("r","",$string);
Заменить все повторяющиеся пробелы на один
Не пытайтесь здесь применить str_replace, это хорошая функция, но не
для данного примера.
$string=preg_replace("/ХХ+/","Х",$string); // вместо Х поставьте пробел
Удаление многократно повторяющихся знаков препинания
Удаление знаков препинания, которые повторяются больше 3 раз, т.е. !!!!! -> !!!, ????? -> ??? и т.д.
Заменяются следующие символы: . ! ? ( )
$text = preg_replace('#(.|?|!|(|)){3,}#', '111', $text);
Сложная замена
В тексте есть некоторые слова, допустим «СЛОВО» и «ЛЯЛЯЛЯ» (и т.д.),
которые нужно одинаковым образом заменить на тоже самое, но
с добавками. Возможно, слова отсутствуют или встречаются много раз
в любом регистре.
Т.е. если было «слово» или «СлОвО» (или еще как),
нужно заменить это на «<b>слово</b>» или «<b>СлОвО</b>» (смотря, как было).
Другими словами нужно найти перечень слов в любом регистре и вставить
по краям найленных слов фиксированные строки (на «<b>» и «</b>»).
$string=preg_replace("/(слово1|слово2|ляляля|слово99)/si","<b>\1</b>",$string);
Проверка URL на корректность
Поддерживает все, что только может быть в УРЛ…
Помните о том, что вы должны не только проверять, но и принимать новое значение
от функции, т.к. та дописывает «http://» в случае его отсутствия.
// функция для удаления опасных сиволов
function pregtrim($str) {
return preg_replace("/[^x20-xFF]/","",@strval($str));
}
//
// проверяет URL и возвращает:
// * +1, если URL пуст
// if (checkurl($url)==1) echo "пусто"
// * -1, если URL не пуст, но с ошибками
// if (checkurl($url)==-1) echo "ошибка"
// * строку (новый URL), если URL найден и отпарсен
// if (checkurl($url)==0) echo "все ок"
// либо if (strlen(checkurl($url))>1) echo "все ок"
//
// Если протокола не было в URL, он будет добавлен ("http://")
//
function checkurl($url) {
// режем левые символы и крайние пробелы
$url=trim(pregtrim($url));
// если пусто - выход
if (strlen($url)==0) return 1;
//проверяем УРЛ на правильность
if (!preg_match("~^(?:(?:https?|ftp|telnet)://(?:[a-z0-9_-]{1,32}".
"(?::[a-z0-9_-]{1,32})?@)?)?(?:(?:[a-z0-9-]{1,128}.)+(?:com|net|".
"org|mil|edu|arpa|gov|biz|info|aero|inc|name|[a-z]{2})|(?!0)(?:(?".
"!0[^.]|255)[0-9]{1,3}.){3}(?!0|255)[0-9]{1,3})(?:/[a-z0-9.,_@%&".
"?+=~/-]*)?(?:#[^ '"&<>]*)?$~i",$url,$ok))
return -1; // если не правильно - выход
// если нет протокала - добавить
if (!strstr($url,"://")) $url="http://".$url;
// заменить протокол на нижний регистр: hTtP -> http
$url=preg_replace_callback("~^[a-z]+~i",'strtolower',$url);
return $url;
}
Таким образом для проверки нужно использовать нечто такое:
$url=checkurl($url); // перезаписали УРЛ в самого себя
if ($url) exit("Ошибочный URL");
// Returns true if «abc» is found anywhere in $string.
preg_match("/abc/", $string);
// Returns true if «abc» is found at the beginning of $string.
preg_match("/^abc/", $string);
// Returns true if «abc» is found at the end of $string.
preg_match("/abc$/", $string);
Возвращает true если browser = Netscape 2, 3 or MSIE 3.
preg_match("/(ozilla.[23]|MSIE.3)/i", $_SERVER["HTTP_USER_AGENT"]);
// Places three space separated words into $regs[1], $regs[2] and $regs[3].
preg_match("/([[:alnum:]]+) ([[:alnum:]]+) ([[:alnum:]]+)/i", $string, $regs);Добавить <br> в начало всех строк
$string = preg_replace("/^/", "<br>", $string);Добавить <br> в конец всех строк
$string = preg_replace("/$/", "<br>", $string);Удалить все аттрибуты у всех тегов, кроме a, p, img
preg_replace("/<([^ap(img)].*?)s.*?>/is", "<\1>", $string);Выбрать локальные URL
Как можно выбрать не просто все урлы в HTML странице а те которые не начинаются на http://, другими словами локальные.
preg_match_all("#s(?:href|src|url)=(?:["'])?(.*?)(?:["'])?(?:[s>])#i", $buffer, $matches);Выбрать все параметры:
$string = '<table border='0' cellpadding = "0" cellspacing=0 style= "border-collapse: collapse">';
if (preg_match_all('#s+([^=s]+)s*=s*((?(?="|') (?:"|')([^"']+)(?:"|') | ([^s]+)))#isx', $string, $matches)) {
print_r($matches);
}Array (
[0] => Array ( [0] => border=’0′ [1] => cellpadding = «0» [2] => cellspacing=0 [3] => style= «border-collapse: collapse» )
[1] => Array ( [0] => border [1] => cellpadding [2] => cellspacing [3] => style )
[2] => Array ( [0] => ‘0’ [1] => «0» [2] => 0 [3] => «border-collapse: collapse» )
[3] => Array ( [0] => 0 [1] => 0 [2] => [3] => border-collapse: collapse )
[4] => Array ( [0] => [1] => [2] => 0 [3] => )
)
А если использовать параметр PREG_SET_ORDER:
$string = '<table border='0' cellpadding = "0" cellspacing=0 style= "border-collapse: collapse">';
if (preg_match_all('#s+([^=s]+)s*=s*((?(?="|') (?:"|')([^"']+)(?:"|') | ([^s]+)))#isx', $string, $matches, PREG_SET_ORDER)) {
print_r($matches);
}Array (
[0] => Array ( [0] => border=’0′ [1] => border [2] => ‘0’ [3] => 0 )
[1] => Array ( [0] => cellpadding = «0» [1] => cellpadding [2] => «0» [3] => 0 )
[2] => Array ( [0] => cellspacing=0 [1] => cellspacing [2] => 0 [3] => [4] => 0 )
[3] => Array ( [0] => style= «border-collapse: collapse» [1] => style [2] => «border-collapse: collapse» [3] => border-collapse: collapse ) )
Конвертор HTML в текст
// $document на выходе должен содержать HTML-документ.
// Необходимо удалить все HTML-теги, секции javascript,
// пробельные символы. Также необходимо заменить некоторые
// HTML-сущности на их эквивалент.
$search = array ("'<script[^>]*?>.*?</script>'si", // Вырезает javaScript
"'<[/!]*?[^<>]*?>'si", // Вырезает HTML-теги
"'([rn])[s]+'", // Вырезает пробельные символы
"'&(quot|#34);'i", // Заменяет HTML-сущности
"'&(amp|#38);'i",
"'&(lt|#60);'i",
"'&(gt|#62);'i",
"'&(nbsp|#160);'i",
"'&(iexcl|#161);'i",
"'&(cent|#162);'i",
"'&(pound|#163);'i",
"'&(copy|#169);'i",
"'&#(d+);'e"); // интерпретировать как php-код
$replace = array ("",
"",
"\1",
""",
"&",
"<",
">",
" ",
chr(161),
chr(162),
chr(163),
chr(169),
"chr(\1)");
$text = preg_replace($search, $replace, $document);
Найти и заменить все «http://» на ссылки
Вариант 1:
$text = preg_replace('#(?<!])bhttp://[^s[<]+#i',
"<a href="$0" target=_blank><u>Посмотреть на сайте</u></a>",
nl2br(stripslashes($text)));
Вариант 2, с выделением домена:
// Cuts off long URLs at $url_length, and appends "..."
function reduceurl($url, $url_length) {
$reduced_url = substr($url, 0, $url_length);
if (strlen($url) > $url_length) $reduced_url .= '...';
return $reduced_url;
}
$linktext = preg_replace_callback("#[(([a-zA-Z]+://)([a-zA-Z0-9?&%.;:/=+_-]*))]#",
function($matches){
return '<a href="'.$matches[1].'" target="_blank">' . reduceurl("'.$matches[3].'", 30) . '</a>';
}, $linktext);
Еще один вариант, учитывающий «WWW.»
// match protocol://address/path/file.extension?some=variable&another=asf%
$text = preg_replace("/s(([a-zA-Z]+://)([a-z][a-z0-9_..-]*[a-z]{2,6})([a-zA-Z0-9/*-?&%]*))s/i", " <a href="$1">$3</a> ", $text);
// match www.something.domain/path/file.extension?some=variable&another=asf%
$text = preg_replace("/s(www.([a-z][a-z0-9_..-]*[a-z]{2,6})([a-zA-Z0-9/*-?&%]*))s/i", " <a href="http://$1">$2</a> ", $text);
Разбор адесов E-mail.
<?
$text = "Адреса: user-first@mail.ru, second.user@mail.ru.";
$html = preg_replace(
'{
[w-.]+ # имя ящика
@
[w-]+(.[w-]+)* # имя хоста
}xs',
'<a href="mailto:$0">$0</a>',
$text
);
echo $html;
?>Результат работы примера:
Адреса: <a href="mailto:user-first@mail.ru">user-first@mail.ru</a>, <a href="mailto:second.user@mail.ru">second.user@mail.ru</a>То же самое, но немножко по-другому:
$html = preg_replace( '/(S+)@([a-z0-9.-]+)/is', '<a href="mailto:$0">$0</a>', $text);
Проверить, что в строке есть число (одна или более цифра)
preg_match('/(d+)/s', "article_123.html", $pockets);
// Совпадение (подвыражение в скобках) окажется в $pockets[1].
echo $pockets[1]; // выводит 123
Найти в тексте адрес E-mail
// S означает "не пробел", а [a-z0-9.]+ -
// "любое число букв, цифр или точек". Модификатор 'i' после '/'
// заставляет PHP не учитывать регистр букв при поиске совпадений.
// Модификатор 's', стоящий рядом с 'i', говорит, что мы работаем
// в "однострочном режиме" (см. ниже в этой главе).
preg_match('/(S+)@([a-z0-9.]+)/is', "Привет от somebody@mail.ru!", $p);
// Имя хоста будет в $p[2], а имя ящика (до @) - в $p[1].
echo "В тексте найдено: ящик - $p[1], хост - $p[2]";
Превращение E-mail в HTML-ссылку.
$text = "Привет от somebody@mail.ru, а также от other@mail.ru!"; $html = preg_replace( '/(S+)@([a-z0-9.]+)/is', // найти все E-mail '<a href="mailto:$0">$0</a>', // заменить их по шаблону $text // искать в $text ); echo $html;
Простейший разбор даты.
$str = " 15-16/2000 "; // к примеру
$re = '{
^s*( # начало строки
(d+) # день
s* [[:punct:]] s* # разделитель
(d+) # месяц
s* [[:punct:]] s* # разделитель
(d+) # год
)s*$ # конец строки
}xs';
// Разбиваем строку на куски при помощи preg_match().
preg_match($re, $str, $pockets) or die("Not a date: $str");
// Теперь разбираемся с карманами.
echo "Дата без пробелов: '$pockets[1]' <br>";
echo "День: $pockets[2] <br>";
echo "Месяц: $pockets[3] <br>";
echo "Год: $pockets[4] <br>";Результат работы примера:
Дата без пробелов: ’15-16/2000′
День: 15
Месяц: 16
Год: 2000
Замена по шаблону
$text = htmlspecialchars(file_get_contents(__FILE__));
$html = preg_replace('/($[a-z]w*)/is', '<b>$1</b>', $text);
echo "<pre>$html</pre>";
Получение обрамляющего тега
$str = "Hello, this <b>word</b> is bold!";
$re = '|<(w+) [^>]* > (.*?) </1>|xs';
preg_match($re, $str, $pockets) or die("Нет тэгов.");
echo htmlspecialchars("'$pockets[2]' обрамлено тэгом '$pockets[1]'");Результат работы примера: ‘word’ обрамлено тэгом ‘b’
Сравнение «жадных» и «ленивых» квантификаторов
$str = '[b]жирный текст [b]а тут - еще жирнее[/b] вернулись[/b]';
$to = '<b>$1</b>';
$re1 = '|[b] (.*) [/b]|ixs';
$re2 = '|[b] (.*?) [/b]|ixs';
$result = preg_replace($re1, $to, $str);
echo "Жадная версия: ".htmlspecialchars($result)."<br />";
$result = preg_replace($re2, $to, $str);
echo "Ленивая версия: ".htmlspecialchars($result)."<br />";Результат работы примера:
Жадная версия: <b>жирный текст [b]а тут - еще жирнее[/b] вернулись</b>
Ленивая версия: <b>жирный текст [b]а тут - еще жирнее</b> вернулись[/b]Многострочность.
$str = file_get_contents(__FILE__);
$str = preg_replace('/^/m', "t", $str);
echo "<pre>".htmlspecialchars($str)."</pre>";
Использование PREG_OFFSET_CAPTURE
$st = '<b>жирный текст</b>';
$re = '|<(w+).*?>(.*?)</1>|s';
preg_match($re, $st, $p, PREG_OFFSET_CAPTURE);
echo "<pre>"; print_r($p); echo "</pre>";Результат работы примера:
Array
(
[0] => Array(
[0] => <b>жирный текст</b>
[1] => 0
)
[1] => Array(
[0] => b
[1] => 1
)
[2] => Array(
[0] => жирный текст
[1] => 3
)
)Применение preg_grep()
foreach (preg_grep('/^exd/s', glob("*")) as $fn)
echo "Файл примера: $fn<br />";
Различные флаги preg_match_all()
<?
Header("Content-type: text/plain");
$flags = array(
"PREG_PATTERN_ORDER",
"PREG_SET_ORDER",
"PREG_SET_ORDER|PREG_OFFSET_CAPTURE",
);
$re = '|<(w+).*?>(.*?)</1>|s';
$text = "<b>текст</b> и еще <i>другой текст</i>";
echo "Строка: $textn";
echo "Выражение: $renn";
foreach ($flags as $name) {
preg_match_all($re, $text, $pockets, eval("return $name;"));
echo "Флаг $name:n";
var_export($pockets);
echo "n";
}
?>Результат работы примера:
Строка: <b>текст</b> и еще <i>другой текст</i>
Выражение: |<(w+).*?>(.*?)</1>|s
Флаг PREG_PATTERN_ORDER: array (
0 => array ( 0 => '<b>текст</b>', 1 => '<i>другой текст</i>', ),
1 => array ( 0 => 'b', 1 => 'i', ),
2 => array ( 0 => 'текст', 1 => 'другой текст', ),
)
Флаг PREG_SET_ORDER: array (
0 => array ( 0 => '<b>текст</b>', 1 => 'b', 2 => 'текст', ),
1 => array ( 0 => '<i>другой текст</i>', 1 => 'i', 2 => 'другой текст', ),
)
Флаг PREG_SET_ORDER|PREG_OFFSET_CAPTURE: array (
0 => array ( 0 => array ( 0 => '<b>текст</b>', 1 => 0, ),
1 => array ( 0 => 'b', 1 => 1, ),
2 => array ( 0 => 'текст', 1 => 3, ), ),
1 => array (
0 => array ( 0 => '<i>другой текст</i>', 1 => 20, ),
1 => array ( 0 => 'i', 1 => 21, ),
2 => array ( 0 => 'другой текст', 1 => 23, ),
),
)preg_replace_callback()
// Пользовательская функция. Будет вызываться для каждого
// совпадения с регулярным выражением.
function toUpper($pockets) {
return $pockets[1].strtoupper($pockets[2]).$pockets[3];
}
$str = '<hTmL><bOdY bgcolor="white">Three captains, one ship.</bOdY></html>';
$str = preg_replace_callback('{(</?)(w+)(.*?>)}s', "toUpper", $str);
echo htmlspecialchars($str);Результат работы примера:
<HTML><BODY bgcolor="white">Three captains, one ship.</BODY></HTML>Получение строки GET-запроса.
Для начала поставим самую простую задачу — получить часть URL, содержащую GET-параметры.
function ggp($url) { // get GET-parameters string
preg_match('/^(.+?)(?.*?)?(#.*)?$/', $url, $matches);
$gp = (isset($matches[2])) ? $matches[2] : '';
return $gp;
}
Не стоит забывать, что адрес может вовсе не содержать никакого GET-запроса, и массив вхождений может не иметь второго элемента 3.
Исключение GET-запроса из URL.
Иногда нужно получить URL без GET-параметров (например, при перенаправлении запросов
с помощью mod_rewrite зачастую требуется проводить анализ URL,
чтобы сформировать ответ клиенту;
нередко для анализа нужна только статическая часть URL,
а часть, где передается GET-запрос, не нужна и даже мешает).
// удаление GET-параметров из URL
$str = preg_replace('/^(.+?)(?.*?)?(#.*)?$/', '$1$3', $url);
заменить все символы кроме чисел и запятой на »
$value = preg_replace('/[^d,]+/', '', $value); // заменить все символы кроме чисел и запятой на ''
Есть ли в строке параметров сессия (PHPSESSID):
print $_SERVER['REQUEST_URI'].'<br>';
if (preg_match("/=([a-f0-9]{32})&/i", $_SERVER['REQUEST_URI'].'&')){
print 'Да';
// удалить сессию из строки параметров
//print str_replace('&&','&',str_replace('?&','?',preg_replace("/&*sid=([a-f0-9]{32})&*/i", '&', $_SERVER['REQUEST_URI'])));
}
else print 'Нет';
Удалить из строки параметр page и добавить другой page.
Этот пример позволяет заменить один параметр на другой не испортив все остальные параметры строки.
Если Вы найдете более оптимальное решение, присылайте.
$href1=str_replace('&&','&',str_replace('?&','?',preg_replace("/&*page=([0-9]{1,3})&*/i", '&', $_SERVER['REQUEST_URI'])));
$href1=str_replace('?&','?',$href1.(strpos($href1, '?')===false?'?':'&').'page=');
Проверка формата времени. date: mm:hh.
$time = "10:11";
if (!preg_match('/^([0-1][0-9]|[2][0-3]):([0-5][0-9])$/', $time)) echo "Время введено неправильно";
Как вытащить слова из текста?
Это регулярное выражение PHP разбирает текст на отдельные слова, основываясь на определении:
слово — это непрерывная последовательность букв английского или русского алфавитов.
$x="Типа, %^& читайте___люди~~~~__маны__ На... РУССКОМ!! Будете+здоровы. abc, qwe, zxc";
preg_match_all('/([a-zA-Zа-яА-Я]+)/',$x,$ok);
for ($i=0; $i<count($ok[1]); $i++) echo $ok[1][$i]."<br>";
Результат будет таким:
Типа
читайте
люди
маны
На
РУССКОМ
Будете
здоровы
abc
qwe
zxc
Как заставить работать с русскими буквами в UTF-8?
В PHP это решается вот так:
preg_replace("/[^p{L}0-9+-_:.@ ]/u", "", $_string));
p{L} = все буквы
/u = работать с UTF-8
Выбрать фразы и слова
Если Вы хотите учитывать слова, заключенные в кавычки, то вам понадобиться такое регулярное выражение:
$search_expression = "apple bear "Tom Cruise" or 'Mickey Mouse' another word";
$words = preg_split("/[s,]*\"([^\"]+)\"[s,]*|" . "[s,]*'([^']+)'[s,]*|" . "[s,]+/", $search_expression, 0, PREG_SPLIT_NO_EMPTY | PREG_SPLIT_DELIM_CAPTURE);
print_r($words);Вы получите отдельные слова и фразы в кавычках:
Array ( [0] => apple [1] => bear [2] => Tom Cruise [3] => or [4] => Mickey Mouse [5] => another [6] => word )
Поиск в тексте российских мобильных номеров телефонов
Уверенно парсит номера вот такого вида:
8 910 82 570 26
+79261234567
89261234567
79261234567
+7 926 123 45 67
8(926)123-45-67
8 (926)123-45-67
8-(926)123-45-67
9261234567
79261234567
89261234567
8-926-123-45-67
8 927 1234 234
8 927 12 12 888
8 927 12 555 12
8 927 123 8 123
preg_match_all('/(8|7|+7){0,1}[- \\(]{0,}([9][0-9]{2})[- \\)]{0,}(([0-9]{2}[- ]{0,}'.
'[0-9]{2}[- ]{0,}[0-9]{3})|([0-9]{3}[- ]{0,}[0-9]{2}[- ]{0,}[0-9]{2})|([0-9]{3}[- ]{0,}'
'[0-9]{1}[- ]{0,}[0-9]{3})|([0-9]{2}[- ]{0,}[0-9]{3}[- ]{0,}[0-9]{2}))/',
$text, $regs );
Для проверки номеров телефонов возможно использование следующих регулярных выражений
По всем странам:
/^+?([87](?!95[4-79]|99[08]|907|94[^0]|336|986)([348]d|9[0-6789]|7[0247])d{8}|
[1246]d{9,13}|68d{7}|5[1-46-9]d{8,12}|55[1-9]d{9}|55[12]19d{8}|500[56]d{4}|
5016d{6}|5068d{7}|502[45]d{7}|5037d{7}|50[4567]d{8}|50855d{4}|509[34]d{7}|
376d{6}|855d{8}|856d{10}|85[0-4789]d{8,10}|8[68]d{10,11}|8[14]d{10}|82d{9,10}|
852d{8}|90d{10}|96(0[79]|17[01]|13)d{6}|96[23]d{9}|964d{10}|96(5[69]|89)d{7}|
96(65|77)d{8}|92[023]d{9}|91[1879]d{9}|9[34]7d{8}|959d{7}|989d{9}|97d{8,12}|
99[^4568]d{7,11}|994d{9}|9955d{8}|996[57]d{8}|9989d{8}|380[34569]d{8}|381d{9}|
385d{8,9}|375[234]d{8}|372d{7,8}|37[0-4]d{8}|37[6-9]d{7,11}|30[69]d{9}|34[67]d{8}|
3[12359]d{8,12}|36d{9}|38[1679]d{8}|382d{8,9}|46719d{10})$/
По СНГ:
/^((+?7|8)(?!95[4-79]|99[08]|907|94[^0]|336|986)([348]d|9[0-6789]|7[0247])d{8}|
+?(99[^4568]d{7,11}|994d{9}|9955d{8}|996[57]d{8}|9989d{8}|380[34569]d{8}|
375[234]d{8}|372d{7,8}|37[0-4]d{8}))$/
Россия:
/^+?(79|73|74|78)/
Украина:
/^+?380/
Казахстан:
K’cell:
/^+?(7701|7702|7775|7778)/
Билайн:
/^+?(7777|7705|7771|7776)/
Теле2:
/^+?(7707|7747)/
Pathword:
/^+?(7700|7717|7727|7725|7721|7718|7713|7712)/
СНГ:
/^+?(7940|374|375|995|996|370|992|993|998)/
Конвертация BR в символ новой строки
Учитывает варианты:
<br>, <br/>, <br />, <BR>, <BR/>, <BR />function br2nl( $input ) {
return preg_replace('/<br(s+)?/?>/i', "n", $input);
}Парсинг логов Apache
Большинство сайтов запущено на всем известном веб-сервере Apache. Если ваш сайт находится в их числе,
почему бы не использовать PHP и регулярные выражения для разбора логов апача?
//Successful hits to HTML files only. Useful for counting the number of page views.
'^((?#client IP or domain name)S+)s+((?#basic authentication)S+s+S+)s+[((?#date and time)[^]]+)]s+"(?:GET|POST|HEAD) ((?#file)/[^ ?"]+?.html?)??((?#parameters)[^ ?"]+)? HTTP/[0-9.]+"s+(?#status code)200s+((?#bytes transferred)[-0-9]+)s+"((?#referrer)[^"]*)"s+"((?#user agent)[^"]*)"$'//404 errors only
'^((?#client IP or domain name)S+)s+((?#basic authentication)S+s+S+)s+[((?#date and time)[^]]+)]s+"(?:GET|POST|HEAD) ((?#file)[^ ?"]+)??((?#parameters)[^ ?"]+)? HTTP/[0-9.]+"s+(?#status code)404s+((?#bytes transferred)[-0-9]+)s+"((?#referrer)[^"]*)"s+"((?#user agent)[^"]*)"$'Замена двойных кавычек “умными” кавычками
Если вы любитель типографики, вам понравится это регулярное выражение, заменяющее обычные двойные кавычки, на “умные кавычки”.
preg_replace('B"b([^"x84x93x94rn]+)b"B', '«1»', $text);Комплексная проверка пароля
Это регулярное выражение будет следить за тем, чтобы в текстовое поле было введено не менее шести символов, цифры, дефисы и подчеркивания.
Текстовое поле должно содержать как минимум один символ верхнего регистра, один нижнего регистра и одну цифру.
'A(?=[-_a-zA-Z0-9]*?[A-Z])(?=[-_a-zA-Z0-9]*?[a-z])(?=[-_a-zA-Z0-9]*?[0-9])[-_a-zA-Z0-9]{6,}z'Выделение имени домена
Это регулярное выражение позволяет получить чистое имя домена без протокола и www.
echo "<br>".preg_replace('#https?://(www.)?#','','https://www.htmlweb.ru/ ');
echo "<br>".preg_replace('#https?://(www.)?#','','http://www.htmlweb.ru/ ');
echo "<br>".preg_replace('#https?://(www.)?#','','https://htmlweb.ru/ ');
echo "<br>".preg_replace('#https?://(www.)?#','','http://www.htmlweb.ru/ ');Выделение из robots.txt нужной директивы
echo (preg_match("/Host:(.*?)n/imU", "User-agent: *
Disallow:
Disallow: /admin/
Sitemap: atlow.ru/sitemap.xml
"."n", $tmp)===false? '' : $tmp[1] );Описание регулярных выражений
Регулярные выражения для самых маленьких
Время прочтения
11 мин
Просмотры 207K
Привет, Хабр.
Меня зовут Виталий Котов и я немного знаю о регулярных выражениях. Под катом я расскажу основы работы с ними. На эту тему написано много теоретических статей. В этой статье я решил сделать упор на количество примеров. Мне кажется, что это лучший способ показать возможности этого инструмента.
Некоторые из них для наглядности будут показаны на примере языков программирования PHP или JavaScript, но в целом они работают независимо от ЯП.
Из названия понятно, что статья ориентирована на самый начальный уровень — тех, кто еще ни разу не использовал регулярные выражения в своих программах или делал это без должного понимания.
В конце статьи я в двух словах расскажу, какие задачи нельзя решить регулярными выражениями и какие инструменты для этого стоит использовать.
Поехали!

Вступление
Регулярные выражения — язык поиска подстроки или подстрок в тексте. Для поиска используется паттерн (шаблон, маска), состоящий из символов и метасимволов (символы, которые обозначают не сами себя, а набор символов).
Это довольно мощный инструмент, который может пригодиться во многих случая — поиск, проверка на корректность строки и т.д. Спектр его возможностей трудно уместить в одну статью.
В PHP работа с регулярными выражениями заключается в наборе функций, из которых я чаще всего использую следующие:
- preg_match (http://php.net/manual/en/function.preg-match.php)
- preg_match_all (http://php.net/manual/en/function.preg-match-all.php)
- preg_replace (http://php.net/manual/en/function.preg-replace.php)
Для работы с ними нужен текст, в котором мы будем искать или заменять подстроки, а также само регулярное выражение, описывающее правило поиска.
Функции на match возвращают число найденных подстрок или false в случае ошибок. Функция на replace возвращает измененную строку/массив или null в случае ошибки. Результат можно привести к bool (false, если не было найдено значений и true, если было) и использовать вместе с if или assertTrue для обработки результата работы.
В JS чаще всего мне приходится использовать:
- match (https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/match)
- test (https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp/test)
- replace (https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/replace)
Все дальнейшие примеры предлагаю смотреть в https://regex101.com/. Это удобный и наглядный интерфейс для работы с регулярными выражениями.
Пример использования функций
В PHP регулярное выражение — это строка, которая начинается и заканчивается символом-разделителем. Все, что находится между разделителями и есть регулярное выражение.
Часто используемыми разделителями являются косые черты “/”, знаки решетки “#” и тильды “~”. Ниже представлены примеры шаблонов с корректными разделителями:
- /foo bar/
- #^[^0-9]$#
- %[a-zA-Z0-9_-]%
Если необходимо использовать разделитель внутри шаблона, его нужно проэкранировать с помощью обратной косой черты. Если разделитель часто используется в шаблоне, в целях удобочитаемости, лучше выбрать другой разделитель для этого шаблона.
- /http:///
- #http://#
В JavaScript регулярные выражения реализованы отдельным объектом RegExp и интегрированы в методы строк.
Создать регулярное выражение можно так:
let regexp = new RegExp("шаблон", "флаги");
Или более короткий вариант:
let regexp = /шаблон/; // без флагов
let regexp = /шаблон/gmi; // с флагами gmi (изучим их дальше)
Пример самого простого регулярного выражения для поиска:
RegExp: /o/
Text: hello world
В этом примере мы просто ищем все символы “o”.
В PHP разница между preg_match и preg_match_all в том, что первая функция найдет только первый match и закончит поиск, в то время как вторая функция вернет все вхождения.
Пример кода на PHP:
<?php
$text = ‘hello world’;
$regexp = ‘/o/’;
$result = preg_match($regexp, $text, $match);
var_dump(
$result,
$match
);
int(1) // нам вернулось одно вхождение, т.к. после функция заканчивает работу
array(1) {
[0]=>
string(1) "o" // нам вернулось вхождение, аналогичное запросу, так как метасимволов мы пока не использовали
}
Пробуем то же самое для второй функции:
<?php
$text = ‘hello world’;
$regexp = ‘/o/’;
$result = preg_match_all($regexp, $text, $match);
var_dump(
$result,
$match
);
int(2)
array(1) {
[0]=>
array(2) {
[0]=>
string(1) "o"
[1]=>
string(1) "o"
}
}
В последнем случае функция вернула все вхождения, которые есть в нашем тексте.
Тот же пример на JavaScript:
let str = 'Hello world';
let result = str.match(/o/);
console.log(result);
["o", index: 4, input: "Hello world"]
Модификаторы шаблонов
Для регулярных выражений существует набор модификаторов, которые меняют работу поиска. Они обозначаются одиночной буквой латинского алфавита и ставятся в конце регулярного выражения, после закрывающего “/”.
- i — символы в шаблоне соответствуют символам как верхнего, так и нижнего регистра.
- m — по умолчанию текст обрабатывается, как однострочная символьная строка. Метасимвол начала строки ‘^’ соответствует только началу обрабатываемого текста, в то время как метасимвол конца строки ‘$’ соответствует концу текста. Если этот модификатор используется, метасимволы «начало строки» и «конец строки» также соответствуют позициям перед произвольным символом перевода и строки и, соответственно, после, как и в самом начале, и в самом конце строки.
Об остальных модификаторах, используемых в PHP, можно почитать тут.
В JavaScript — тут.
О том, какие вообще бывают модификаторы, можно почитать тут.
Пример предыдущего регулярного выражения с модификатором на JavaScript:
let str = "hello world
How is it going?"
let result = str.match(/o/g);
console.log(result);
["o", "o", "o", "o"]
Метасимволы в регулярных выражениях
Примеры по началу будут довольно примитивные, потому что мы знакомимся с самыми основами. Чем больше мы узнаем, тем ближе к реалиям будут примеры.
Чаще всего мы заранее не знаем, какой текст нам придется парсить. Заранее известен только примерный набор правил. Будь то пинкод в смс, email в письме и т.п.
Первый пример, нам надо получить все числа из текста:
Текст: “Привет, твой номер 1528. Запомни его.”
Чтобы выбрать любое число, надо собрать все числа, указав “[0123456789]”. Более коротко можно задать вот так: “[0-9]”. Для всех цифр существует метасимвол “d”. Он работает идентично.
Но если мы укажем регулярное выражение “/d/”, то нам вернётся только первая цифра. Мы, конечно, можем использовать модификатор “g”, но в таком случае каждая цифра вернется отдельным элементом массива, поскольку будет считаться новым вхождением.
Для того, чтобы вывести подстроку единым вхождением, существуют символы плюс “+” и звездочка “*”. Первый указывает, что нам подойдет подстрока, где есть как минимум один подходящий под набор символ. Второй — что данный набор символов может быть, а может и не быть, и это нормально. Помимо этого мы можем указать точное значение подходящих символов вот так: “{N}”, где N — нужное количество. Или задать “от” и “до”, указав вот так: “{N, M}”.
Сейчас будет пара примеров, чтобы это уложилось в голове:
Текст: “Я хочу ходить на работу 2 раза в неделю.”
Надо получить цифру из тексте.
RegExp: “/d/”
Текст: “Ваш пинкод: 24356” или “У вас нет пинкода.”
Надо получить пинкод или ничего, если его нет.
RegExp: “/d*/”
Текст: “Номер телефона 89091534357”
Надо получить первые 11 символов, или FALSE, если их меньше.
RegExp: “/d{11}/”
Примерно так же мы работает с буквами, не забывая, что у них бывает регистр. Вот так можно задавать буквы:
- [a-z]
- [a-zA-Z]
- [а-яА-Я]
C кириллицей указанный диапазон работает по-разному для разных кодировок. В юникоде, например, в этот диапазон не входит буква “ё”. Подробнее об этом тут.
Пара примеров:
Текст: “Вот бежит олень” или “Вот ваш индюк”
Надо выбрать либо слово “олень”, либо слово “индюк”.
RegExp: “/[а-яА-Я]+/”
Такое выражение выберет все слова, которые есть в предложении и написаны кириллицей. Нам нужно третье слово.
Помимо букв и цифр у нас могут быть еще важные символы, такие как:
- s — пробел
- ^ — начало строки
- $ — конец строки
- | — “или”
Предыдущий пример стал проще:
Текст: “Вот бежит олень” или “Вот бежит индюк”
Надо выбрать либо “олень”, либо “индюк”.
RegExp: “/[а-яА-Я]+$/”
Если мы точно знаем, что искомое слово последнее, мы ставим “$” и результатом работы будет только тот набор символов, после которого идет конец строки.
То же самое с началом строки:
Текст: “Олень вкусный” или “Индюк вкусный”
Надо выбрать либо “олень”, либо “индюк”.
RegExp: “/^[а-яА-Я]+/”
Прежде, чем знакомиться с метасимволами дальше, надо отдельно обсудить символ “^”, потому что он у нас ходит на две работы сразу (это чтобы было интереснее). В некоторых случаях он обозначает начало строки, но в некоторых — отрицание.
Это нужно для тех случаев, когда проще указать символы, которые нас не устраивают, чем те, которые устраивают.
Допустим, мы собрали набор символов, которые нам подходят: “[a-z0-9]” (нас устроит любая маленькая латинская буква или цифра). А теперь предположим, что нас устроит любой символ, кроме этого. Это будет обозначаться вот так: “[^a-z0-9]”.
Пример:
Текст: “Я люблю кушать суп”
Надо выбрать все слова.
RegExp: “[^s]+”
Выбираем все “не пробелы”.
Итак, вот список основных метасимволов:
- d — соответствует любой цифре; эквивалент [0-9]
- D — соответствует любому не числовому символу; эквивалент [^0-9]
- s — соответствует любому символу whitespace; эквивалент [ tnrfv]
- S — соответствует любому не-whitespace символу; эквивалент [^ tnrfv]
- w — соответствует любой букве или цифре; эквивалент [a-zA-Z0-9_]
- W — наоборот; эквивалент [^a-zA-Z0-9_]
- . — (просто точка) любой символ, кроме перевода “каретки”
Операторы [] и ()
По описанному выше можно было догадаться, что [] используется для группировки нескольких символов вместе. Так мы говорим, что нас устроит любой символ из набора.
Пример:
Текст: “Не могу перевести I dont know, помогите!”
Надо получить весь английский текст.
RegExp: “/[A-Za-zs]{2,}/”
Тут мы собрали в группу (между символами []) все латинские буквы и пробел. При помощи {} указали, что нас интересуют вхождения, где минимум 2 символа, чтобы исключить вхождения из пустых пробелов.
Аналогично мы могли бы получить все русские слова, сделав инверсию: “[^A-Za-zs]{2,}”.
В отличие от [], символы () собирают отмеченные выражения. Их иногда называют “захватом”.
Они нужны для того, чтобы передать выбранный кусок (который, возможно, состоит из нескольких вхождений [] в результат выдачи).
Пример:
Текст: ‘Email you sent was ololo@example.com Is it correct?’
Нам надо выбрать email.
Существует много решений. Пример ниже — это приближенный вариант, который просто покажет возможности регулярных выражений. На самом деле есть RFC, который определяет правильность email. И есть “регулярки” по RFC — вот примеры.
Мы выбираем все, что не пробел (потому что первая часть email может содержать любой набор символов), далее должен идти символ @, далее что угодно, кроме точки и пробела, далее точка, далее любой символ латиницы в нижнем регистре…
Итак, поехали:
- мы выбираем все, что не пробел: “[^s]+”
- мы выбираем знак @: “@”
- мы выбираем что угодно, кроме точки и пробела: “[^s.]+”
- мы выбираем точку: “.” (обратный слеш нужен для экранирования метасимвола, так как знак точки описывает любой символ — см. выше)
- мы выбираем любой символ латиницы в нижнем регистре: “[a-z]+”
Оказалось не так сложно. Теперь у нас есть email, собранный по частям. Рассмотрим на примере результата работы preg_match в PHP:
<?php
$text = ‘Email you sent was ololo@example.com. Is it correct?’;
$regexp = ‘/[^s]+@[^s.]+.[a-z]+/’;
$result = preg_match_all($regexp, $text, $match);
var_dump(
$result,
$match
);
int(1)
array(1) {
[0]=>
array(1) {
[0]=>
string(13) "ololo@example.com"
}
}
Получилось! Но что, если теперь нам надо по отдельности получить домен и имя по email? И как-то использовать дальше в коде? Вот тут нам поможет “захват”. Мы просто выбираем, что нам нужно, и оборачиваем знаками (), как в примере:
Было:
/[^s]+@[^s.]+.[a-z]+/
Стало:
/([^s]+)@([^s.]+.[a-z]+)/
Пробуем:
<?php
$text = ‘Email you sent was ololo@example.com. Is it correct?’;
$regexp = ‘/([^s]+)@([^s.]+.[a-z]+)/’;
$result = preg_match_all($regexp, $text, $match);
var_dump(
$result,
$match
);
int(1)
array(3) {
[0]=>
array(1) {
[0]=>
string(13) "ololo@example.com"
}
[1]=>
array(1) {
[0]=>
string(5) "ololo"
}
[2]=>
array(1) {
[0]=>
string(7) "example.com"
}
}
В массиве match нулевым элементом всегда идет полное вхождение регулярного выражения. А дальше по очереди идут “захваты”.
В PHP можно именовать “захваты”, используя следующий синтаксис:
/(?<mail>[^s]+)@(?<domain>[^s.]+.[a-z]+)/
Тогда массив матча станет ассоциативным:
<?php
$text = ‘Email you sent was ololo@example.com. Is it correct?’;
$regexp = ‘/(?<mail>[^s]+)@(?<domain>[^s.]+.[a-z]+)/’;
$result = preg_match_all($regexp, $text, $match);
var_dump(
$result,
$match
);
int(1)
array(5) {
[0]=>
array(1) {
[0]=>
string(13) "ololo@example.com"
}
["mail"]=>
array(1) {
[0]=>
string(5) "ololo"
}
["domain"]=>
array(1) {
[0]=>
string(7) "example.com"
}
}
Это сразу +100 к читаемости и кода, и регулярки.
Примеры из реальной жизни
Парсим письмо в поисках нового пароля:
Есть письмо с HTML-кодом, надо выдернуть из него новый пароль. Текст может быть либо на английском, либо на русском:
Текст: “пароль: <b>f23f43tgt4</b>” или “password: <b>wh4k38f4</b>”
RegExp: “(password|пароль):s<b>([^<]+)</b>”
Сначала мы говорим, что текст перед паролем может быть двух вариантов, использовав “или”.
Вариантов можно перечислять сколько угодно:
(password|пароль)
Далее у нас знак двоеточия и один пробел:
:s
Далее знак тега b:
<b>
А дальше нас интересует все, что не символ “<”, поскольку он будет свидетельствовать о том, что тег b закрывается:
([^<]+)
Мы оборачиваем его в захват, потому что именно он нам и нужен.
Далее мы пишем закрывающий тег b, проэкранировав символ “/”, так как это спецсимвол:
</b>
Все довольно просто.
Парсим URL:
В PHP есть клевая функция, которая помогает работать с урлом, разбирая его на составные части:
<?php
$URL = "https://hello.world.ru/uri/starts/here?get_params=here#anchor";
$parsed = parse_url($URL);
var_dump($parsed);
array(5) {
["scheme"]=>
string(5) "https"
["host"]=>
string(14) "hello.world.ru"
["path"]=>
string(16) "/uri/starts/here"
["query"]=>
string(15) "get_params=here"
["fragment"]=>
string(6) "anchor"
}
Давай сделаем то же самое, только регуляркой? 
Любой урл начинается со схемы. Для нас это протокол http/https. Можно было бы сделать логическое “или”:
(http|https)
Но можно схитрить и сделать вот так:
http[s]?
В данном случае символ “?” означает, что “s” может есть, может нет…
Далее у нас идет “://”, но символ “/” нам придется экранировать (см. выше):
“://”
Далее у нас до знака “/” или до конца строки идет домен. Он может состоять из цифр, букв, знака подчеркивания, тире и точки:
[w.-]+
Тут мы собрали в единую группу метасимвол “w”, точку ”.” и тире ”-”.
Далее идет URI. Тут все просто, мы берем все до вопросительного знака или конца строки:
[^?$]+
Теперь знак вопроса, который может быть, а может не быть:
[?]?
Далее все до конца строки или начала якоря (символ #) — не забываем о том, что этой части тоже может не быть:
[^#$]+
Далее может быть #, а может не быть:
[#]?
Дальше все до конца строки, если есть:
[^$]+
Вся красота в итоге выглядит так (к сожалению, я не придумал, как вставить эту часть так, чтобы Habr не считал часть строки — комментарием):
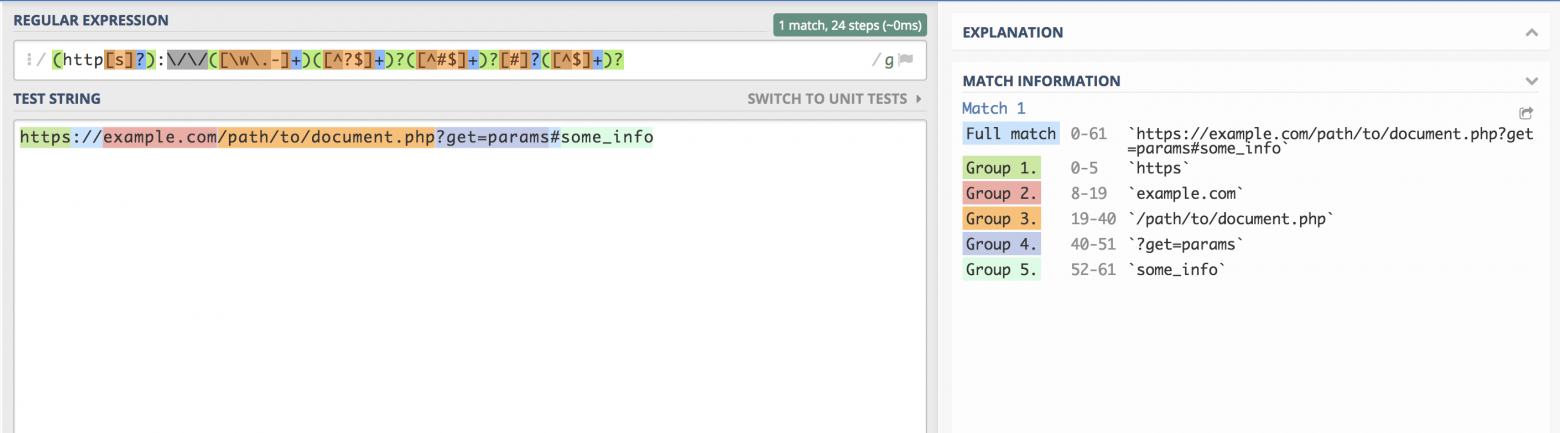
/(?<scheme>http[s]?)://(?<domain>[w.-]+)(?<path>[^?$]+)?(?<query>[^#$]+)?[#]?(?<fragment>[^$]+)?/
Главное не моргать!
<?php
$URL = "https://hello.world.ru/uri/starts/here?get_params=here#anchor";
$regexp = “/(?<scheme>http[s]?)://(?<domain>[w.-]+)(?<path>[^?$]+)?(?<query>[^#$]+)?[#]?(?<fragment>[^$]+)?/”;
$result = preg_match($regexp, $URL, $match);
var_dump(
$result,
$match
);
array(11) {
[0]=>
string(61) "https://hello.world.ru/uri/starts/here?get_params=here#anchor"
["scheme"]=>
string(5) "https"
["domain"]=>
string(14) "hello.world.ru"
["URI"]=>
string(16) "/uri/starts/here"
["params"]=>
string(15) "get_params=here"
["anchor"]=>
string(6) "anchor"
}
Получилось примерно то же самое, только своими руками.
Какие задачи не решаются регулярными выражениями
На первый взгляд кажется, что регулярными выражениями можно описать и распарсить любой текст. Но, к сожалению, это не так.
Регулярные выражении — это подвид формальных языков, который в иерархии Хомского принадлежат 3-ому типу, самому простому. Об этом тут.
При помощи этого языка мы не можем, например, парсить синтаксис языков программирования с вложенной грамматикой. Или HTML код.
Примеры задач:
У нас есть span, внутри которых много других span и мы не знаем сколько. Надо выбрать все, что находится внутри этого span:
<span>
<span>ololo1</span>
<span>ololo2</span>
<span>ololo3</span>
<span>ololo4</span>
<span>ololo5</span>
<...>
</span>
Само собой, если мы парсим HTML, где есть не только этот span.
Суть в том, что мы не можем начать с какого-то момента “считать” символы span и /span, подразумевая, что открывающих и закрывающих символов должно быть равное количество. И “понять”, что закрывающий символ, для которого ранее не было пары — тот самый закрывающий, который обосабливает блок.
То же самое с кодом и символами {}.
Например:
function methodA() {
function() {<...>}
if () { if () {<...>} }
}
В такой структуре мы не сможем при помощи только регулярного выражения отличить закрывающую фигурную скобку внутри кода от той, которая завершает начальную функцию (если код состоит не только из этой функции).
Для решение таких задач используются языки более высокого уровня.
Заключение
Я постарался довольно подробно рассказать об азах мира регулярных выражений. Конечно невозможно в одну статью уместить все. Дальнейшая работа с ними — вопрос опыта и умения гуглить.
Спасибо за внимание.
Регулярное выражение. Валидация номера телефона
Как проверить номер мобильного телефона? Проверка правильности, введенного номера телефона является не сложной, но важной задачей. Если пользователь введет некорректный номер, то смс сообщение до него не дойдет.
PHP проверка сотового телефона позволяет убедится, что номер телефона содержит только цифры: без тире, пробелов, дефисов, скобок и т.д. Часто владельцы прямых номеров не вводят свой код, а он необходим для отправки смс сообщения. Не зная префикса, можно только позвонить на данный номер, но нельзя отправить смс сообщение. В частном порядке можно позвонить в службы поддержки Билайна, МТС, Мегафона и попытаться выяснить какой префикс у данного прямого номера. Операторы предоставляют данную информацию.
Однако, чтобы избежать данных проблем, мы предлагаем обрабатывать вводимый клиентом телефон на сайте уже в момент его регистрации. Это позволит вам гарантированно доставлять смс сообщения через php на телефон вашего клиента.
/**
* проверка - телефон ли
* @param $_val
* @return bool
*/
function is_phone($_val)
{
if (empty($_val)) {
return false;
}
if (!preg_match('/^+?d{10,15}$/', $_val)) {
return false;
}
if (
(mb_substr($_val, 0, 2) == '+7' and mb_strlen($_val) != 12) ||
(mb_substr($_val, 0, 1) == '7' and mb_strlen($_val) != 11) ||
(mb_substr($_val, 0, 1) == '8' and mb_strlen($_val) == 11) ||
(mb_substr($_val, 0, 1) == '9' and mb_strlen($_val) == 11)
) {
return false;
}
return true;
}
- Регулярные выражения
- PHP
- примеры
 This solution actually validates the numbers and the format. For example: 123-456-7890 is a valid format but is NOT a valid US number and this answer bears that out where others here do not.
This solution actually validates the numbers and the format. For example: 123-456-7890 is a valid format but is NOT a valid US number and this answer bears that out where others here do not.
If you do not want the extension capability remove the following including the parenthesis:
(?:s*(?:#|x.?|ext.?|extension)s*(d+)s*)?
edit (addendum) I needed this in a client side only application so I converted it. Here it is for the javascript folks:
var myPhoneRegex = /(?:(?:+?1s*(?:[.-]s*)?)?(?:(s*([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9])s*)|([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9]))s*(?:[.-]s*)?)([2-9]1[02-9]|[2-9][02-9]1|[2-9][02-9]{2})s*(?:[.-]s*)?([0-9]{4})s*(?:s*(?:#|x.?|ext.?|extension)s*(d+)s*)?$/i;
if (myPhoneRegex.test(phoneVar)) {
// Successful match
} else {
// Match attempt failed
}
hth.
end edit
This allows extensions or not and works with .NET
(?:(?:+?1s*(?:[.-]s*)?)?(?:(s*([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9])s*)|([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9]))s*(?:[.-]s*)?)([2-9]1[02-9]|[2-9][02-9]1|[2-9][02-9]{2})s*(?:[.-]s*)?([0-9]{4})(?:s*(?:#|x.?|ext.?|extension)s*(d+))?$
To validate with or without trailing spaces. Perhaps when using .NET validators and trimming server side use this slightly different regex:
(?:(?:+?1s*(?:[.-]s*)?)?(?:(s*([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9])s*)|([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9]))s*(?:[.-]s*)?)([2-9]1[02-9]|[2-9][02-9]1|[2-9][02-9]{2})s*(?:[.-]s*)?([0-9]{4})s*(?:s*(?:#|x.?|ext.?|extension)s*(d+)s*)?$
All valid:
1 800 5551212
800 555 1212
8005551212
18005551212
+1800 555 1212 extension65432
800 5551212 ext3333
Invalid #s
234-911-5678
314-159-2653
123-234-5678
EDIT: Based on Felipe’s comment I have updated this for international.
Based on what I could find out from here and here regarding valid global numbers
This is tested as a first line of defense of course. An overarching element of the international number is that it is no longer than 15 characters. I did not write a replace for all the non digits and sum the result. It should be done for completeness. Also, you may notice that I have not combined the North America regex with this one. The reason is that this international regex will match North American numbers, however, it will also accept known invalid # such as +1 234-911-5678. For more accurate results you should separate them as well.
Pauses and other dialing instruments are not mentioned and therefore invalid per E.164
(?+[0-9]{1,3})? ?-?[0-9]{1,3} ?-?[0-9]{3,5} ?-?[0-9]{4}( ?-?[0-9]{3})?
With 1-10 letter word for extension and 1-6 digit extension:
(?+[0-9]{1,3})? ?-?[0-9]{1,3} ?-?[0-9]{3,5} ?-?[0-9]{4}( ?-?[0-9]{3})? ?(w{1,10}s?d{1,6})?
Valid International: Country name for ref its not a match.
+55 11 99999-5555 Brazil
+593 7 282-3889 Ecuador
(+44) 0848 9123 456 UK
+1 284 852 5500 BVI
+1 345 9490088 Grand Cayman
+32 2 702-9200 Belgium
+65 6511 9266 Asia Pacific
+86 21 2230 1000 Shanghai
+9124 4723300 India
+821012345678 South Korea
And for your extension pleasure
+55 11 99999-5555 ramal 123 Brazil
+55 11 99999-5555 foo786544 Brazil
Enjoy
This solution actually validates the numbers and the format. For example: 123-456-7890 is a valid format but is NOT a valid US number and this answer bears that out where others here do not.
If you do not want the extension capability remove the following including the parenthesis:
(?:s*(?:#|x.?|ext.?|extension)s*(d+)s*)?
edit (addendum) I needed this in a client side only application so I converted it. Here it is for the javascript folks:
var myPhoneRegex = /(?:(?:+?1s*(?:[.-]s*)?)?(?:(s*([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9])s*)|([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9]))s*(?:[.-]s*)?)([2-9]1[02-9]|[2-9][02-9]1|[2-9][02-9]{2})s*(?:[.-]s*)?([0-9]{4})s*(?:s*(?:#|x.?|ext.?|extension)s*(d+)s*)?$/i;
if (myPhoneRegex.test(phoneVar)) {
// Successful match
} else {
// Match attempt failed
}
hth.
end edit
This allows extensions or not and works with .NET
(?:(?:+?1s*(?:[.-]s*)?)?(?:(s*([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9])s*)|([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9]))s*(?:[.-]s*)?)([2-9]1[02-9]|[2-9][02-9]1|[2-9][02-9]{2})s*(?:[.-]s*)?([0-9]{4})(?:s*(?:#|x.?|ext.?|extension)s*(d+))?$
To validate with or without trailing spaces. Perhaps when using .NET validators and trimming server side use this slightly different regex:
(?:(?:+?1s*(?:[.-]s*)?)?(?:(s*([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9])s*)|([2-9]1[02-9]|[2-9][02-8]1|[2-9][02-8][02-9]))s*(?:[.-]s*)?)([2-9]1[02-9]|[2-9][02-9]1|[2-9][02-9]{2})s*(?:[.-]s*)?([0-9]{4})s*(?:s*(?:#|x.?|ext.?|extension)s*(d+)s*)?$
All valid:
1 800 5551212
800 555 1212
8005551212
18005551212
+1800 555 1212 extension65432
800 5551212 ext3333
Invalid #s
234-911-5678
314-159-2653
123-234-5678
EDIT: Based on Felipe’s comment I have updated this for international.
Based on what I could find out from here and here regarding valid global numbers
This is tested as a first line of defense of course. An overarching element of the international number is that it is no longer than 15 characters. I did not write a replace for all the non digits and sum the result. It should be done for completeness. Also, you may notice that I have not combined the North America regex with this one. The reason is that this international regex will match North American numbers, however, it will also accept known invalid # such as +1 234-911-5678. For more accurate results you should separate them as well.
Pauses and other dialing instruments are not mentioned and therefore invalid per E.164
(?+[0-9]{1,3})? ?-?[0-9]{1,3} ?-?[0-9]{3,5} ?-?[0-9]{4}( ?-?[0-9]{3})?
With 1-10 letter word for extension and 1-6 digit extension:
(?+[0-9]{1,3})? ?-?[0-9]{1,3} ?-?[0-9]{3,5} ?-?[0-9]{4}( ?-?[0-9]{3})? ?(w{1,10}s?d{1,6})?
Valid International: Country name for ref its not a match.
+55 11 99999-5555 Brazil
+593 7 282-3889 Ecuador
(+44) 0848 9123 456 UK
+1 284 852 5500 BVI
+1 345 9490088 Grand Cayman
+32 2 702-9200 Belgium
+65 6511 9266 Asia Pacific
+86 21 2230 1000 Shanghai
+9124 4723300 India
+821012345678 South Korea
And for your extension pleasure
+55 11 99999-5555 ramal 123 Brazil
+55 11 99999-5555 foo786544 Brazil
Enjoy